Scrapy2.7速通
注意:据我观察,scrapy很多版本的文档都不大一样。在一些早期版本,有好心人将英文文档翻译成中文(大概率是机翻或者AI翻的),而在最新版本中内容又不一样。因此建议参考的路径是 pip官网scrapy主页查看最新版本,并找到相关最新的文档。(不是说旧版文档不能用,每个文档都有差别容易,让人摸不着头脑)
scrapy简单调用过程
爬虫通过向start_urls发送请求,调用默认的回调函数,并将相应对象作为参数传给它
在回调函数中,使用css选择器遍历元素,将寻找到的结果生成一个字典通过生成器返回,并找到下一个链接继续使用回调函数。
scrapy的请求调度是异步的,scrapy无需等待上一个请求被处理完,可以同时发送另一个请求继续处理
Scrapy纯代码创建爬虫
1 | |
然后在终端使用下列命令运行该文件,如需设置字符集在后面加上-s FEED_EXPORT_ENCODING='utf-8'
1 | |
问题1:这是一个.py文件,应该可以通过纯代码的方式来运行,但目前位置没有看到相关的教程。
问题2:为什么要用yield而不用return:因为需要重复调用,return会直接退出函数。
通过Scrapy模板快速创建爬虫
创建爬虫项目
注意,在创建项目时,建议不要以某个单功能/网站爬虫来命名。一般以范围比较大的,例如电影爬虫、新闻爬虫等为名。因为一个项目下面允许创建多个爬虫,单个网站的爬虫就放在项目里面,通过模板命令来创建即可
1 | |
通过以上命令,将会创建一个名为stockstar的目录,目录结构如下:
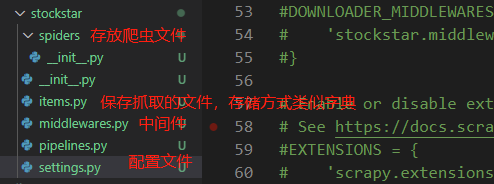
按模板初始化爬虫
1 | |
创建爬虫初始URL和parse函数,在spider目录下创建一个stock.py文件,自动生成start_url和parse函数,爬虫的逻辑就在parse中编写。
运行爬虫
在根目录新建main.py,执行代码运行爬虫
1 | |
这行代码等价于终端执行scrapy crawl myspider -o items.json
如果需要生成其他格式,则执行scrapy crawl myspider -o item.csv/item.xml,如需导出时指定编码格式,则在后面添加-s FEED_EXPORT_ENCODING=utf-8
settings.py配置
1 | |
其他工具
Scrapy Shell
1 | |
创建Scrapy Shell终端,Scrapy将对网页进行访问后返回response,在scrapy shell中可以随意使用选择器进行测试、选取,而不需要多次访问该网页,相当于将该网页的内容下载到本地供你测试使用。
1 | |
scrapy view
通过scrapy view http://xxxxxx.com可以将spider可以爬取到的页面保存到本地或者浏览器打开,在保存到本地后,可以对其进行分析,无需手动对目标页面发请求
scrapy list
在根目录执行scrapy list,可以查看当前项目中所有spider
scrapy settings
格式:scrapy setting --get BOT_NAME获得设定值。
选择器的使用
1 | |
针对上方的HTML结构,不同的选择器有不同的写法。
Xpath选择器
基本用法
格式: response.selector.xpath('//span/text()').get()
获取文本:/text()
获取属性:/@href
过滤标签:
1 | |
即:选择href属性的值包含image的<a>,输出其href值
CSS选择器
基本用法
格式:response.selector.css(‘span::text’).get()
获取文本:::text 或 *::text , 后者用于选择某节点下所有文本
获取属性:::attr("href") 或者 .attrib['href'] , 后者一般用于在唯一元素中使用,因此无需在用get()
过滤标签:
1 | |
即:选择href属性的值包含image的<a>,输出其href值
补充:
1 | |
选择器的其他用法
选择器列表
选择器为所选取的标签构建一个选择器列表SelectorList:
1 | |
返回的是一个列表,因此需要使用get()或getall()来提取文本
当未匹配时返回None,可设置默认返回值: xxx.get(default='not-found')
选择器+正则
xpath和css选择器都支持使用正则表达式提取方法,selector.re()将返回unicode字符串列表
1 | |
选择器连接
单纯的某种选择器可能不太方便使用,scrapy选择器允许在合适的地方联合使用css和xpath
1 | |
嵌套选择器
两种选择器都返回的列表是相同的,既然是列表就可以用于迭代,在迭代过程中,每个元素都可以再次使用选择器来匹配元素
1 | |
如果在内部使用的选择器是xpath,需要注意路径问题:
如果使用相对路径,则需要这样用 ‘.//xx’ 或者 直接选择所需元素,因为外部的选择器已经是根路径
带括号的条件
1 | |
-
带着括号的(node)相当于获取所有符合元素的列表的第[n]个
-
不带括号时对整个response进行筛选,只要符合就取出
例如上面的例子:
'//li[1]'可以匹配到2个<ul>下的<li>, 因为他们都表示li的第一个
而'(//li)[1]'则匹配整个文档中li[1],因为加了括号后整个文档的li是一个整体,只取这个整体里的第一个。
除了自带的选择器,Python还有其他库也可以进行解析:
-
beautifulSoup,根据HTML构造Python对象,缺点是速度慢
-
lxml,可解析xml和HTML,非python标准库
选择器语法大全
CSS选择器
| 表达式 | 说明 |
|---|---|
| * | 所有节点 |
| #ElementId | ID为ElementId的节点 |
| .clsName | class为clsName的节点 |
| li a | li元素下所有a元素 |
| ul + p | ul下第一个P元素 |
| div#eId > ul | id为eId的元素下所有ul元素 |
| div.clsName | clsss为clsName的div元素 |
| ul ~ p | 与ul相邻的所有p元素 |
| a[title] | 所有有tittle属性的a元素 |
| a[href=“http://www.baidu.com”] | 所有href为指定值的a元素 |
| a[href*=“job”] | 所有href属性包含指定值的a元素 |
| a[href^=“http”] | 所有href属性值以指定值开头的a元素 |
| a[href$=“.jpg”] | 素有href属性值以指定值结尾的a元素 |
| input[type=radio]:checked | 状态为选中的radio元素 |
| div:not(#eleId) | 所有id不是指定值的div元素 |
| li:nth-child(3) | 第三个li元素 |
| tr:nth-child(2n) | 第偶数个 tr 元素 |
| 以下选择器未尝试过 | |
| div,p | 选择所有 元素和所有 元素 |
| div>p | 选择父元素为 元素的所有 元素 |
| [title~=flower] | 选择 title 属性包含单词 “flower” 的所有元素 |
| p:first-child | 选择属于父元素的第一个子元素的每个 元素 |
Xpath语法大全
| 表达式 | 说明 |
|---|---|
| div | 选取所有div元素的所有子元素 |
| /div | 选取根元素div |
| div/a | 素有属于div的子元素的a元素 |
| //div | 所有div元素 |
| div//span | 所有属于div元素的后代span元素,无论在那个层级 |
| //@class | 选取所有名为class的属性 |
| /div/p[1] | 属于div子元素的第一个p元素 |
| /div/p[last()] | 属于div子元素的最后一个p元素 |
| /div/p[last()-1] | 属于div子元素的倒数第二个p元素 |
| /div[@lang] | 所有有lang属性的div元素 |
| //div[@lang=‘eng’] | 所有lang属性为eng的div元素 |
| .//header//span[contains(@class,‘main-title-rating’)]/@title | .符号表示当前路径,一般在循环中使用;contains中表示class中包含指定值元素,@title是取元素的title属性 |
| * | 匹配任意元素 |
| @* | 匹配任意属性的元素 |
| node() | 匹配任意类型的元素 |