深入了解JavaScript代码执行流程
前一篇文章简单了解了一下 JS 代码运行时的编译和执行的两个阶段。这里再着重看看执行上下文相关的一些东西。
之前讲,当一段代码被执行时,JS 引擎会先对它进行编译,然后创建上下文,再去执行代码。那么到底什么时候才会开始创建上下文呢?总不能每行代码都创建一个上下文吧?
这里可以理解成,JS 代码只有两个维度,一个是全局维度,一个是函数维度,这样就很好理解了。
(注:这里忽略了块级作用域,因为块级作用域不会创建执行上下文)
一般有如下几种情况会创建执行上下文:
- 当 JS 执行全局代码时,会编译全局代码并创建全局执行上下文,整个页面的生存周期内,全局执行上下文只有一份
- 当调用一个函数时,函数内的代码会被编译,并创建函数执行上下文,一般来说函数执行结束后,函数执行上下文会被销毁
- 当使用eval()函数时,eval内的代码也会被编译,并创建执行上下文。
调用栈
跟Java的内存溢出相似,JavaScript也会出现类似的情况。在运行一段没有终止条件的递归函数时,就会出现栈溢出的情况。
1 | |
函数调用
函数调用就是运行一个函数。如下就是先声明了一个add()函数,然后运行了该函数。
1 | |
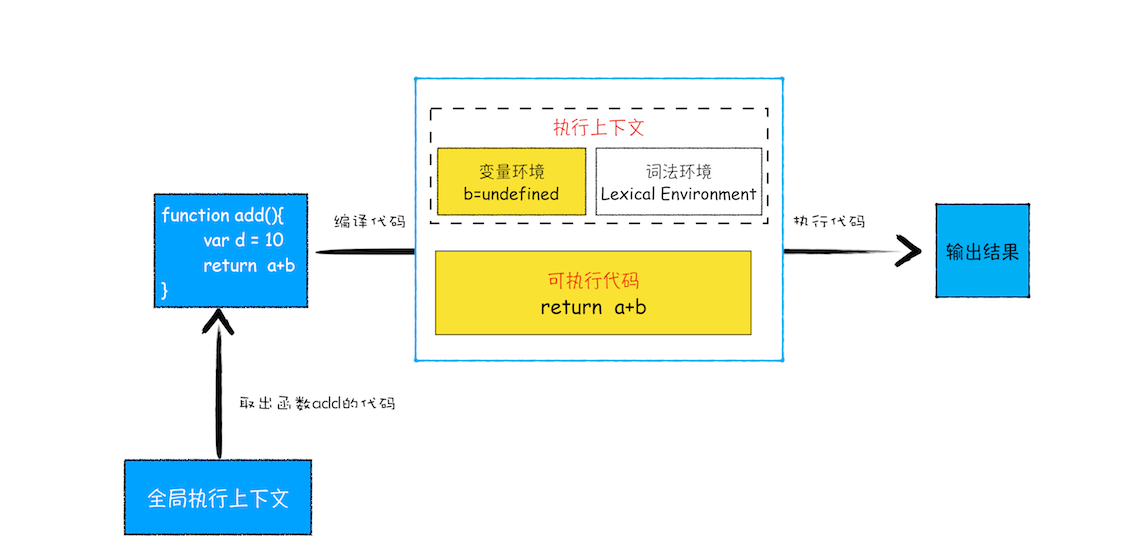
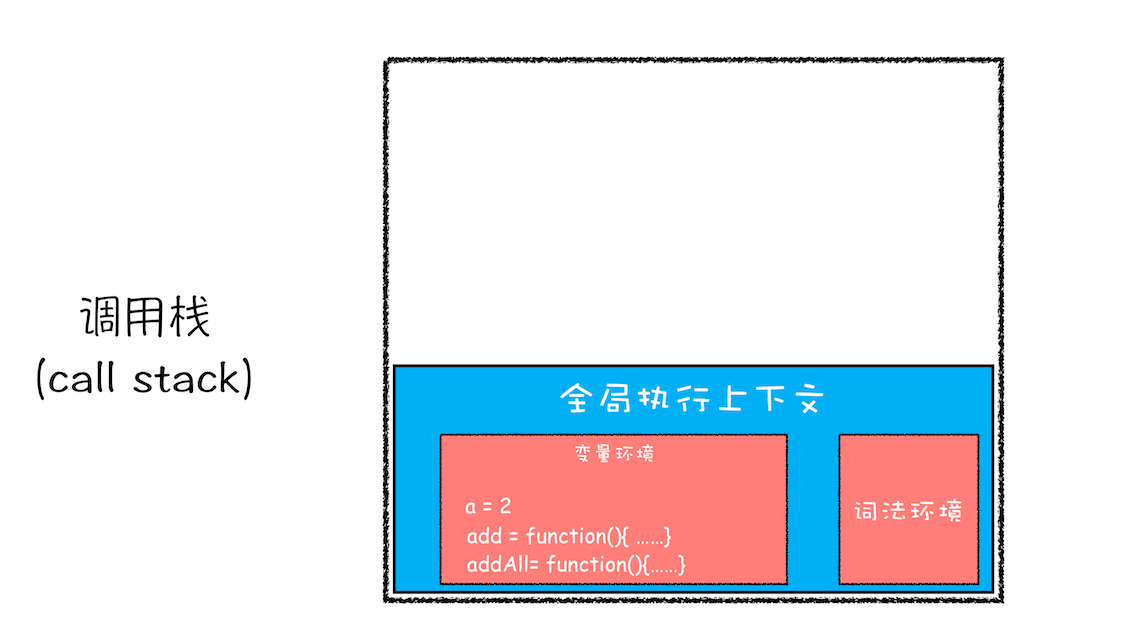
分析:在执行add()之前(注意是之前),JS 引擎为上面的代码创建了全局执行上下文,包含声明的函数和变量,如下:

可以看到所有声明的对象都在全局执行上下文的变量环境中。接着开始执行全局代码,从var a = 2开始,执行到add()。JS 判断这是一个函数调用,那么会执行以下操作:
- 从全局执行上下文中取出这段add函数的代码
- 对add函数这段代码进行编译,并创建该函数的执行上下文和可执行代码。
- 执行该函数的可执行代码。
也就是说,当执行到add函数后,会存在两个执行上下文:全局和add函数
图在下方:
那这跟栈有什么关系?当然有,执行 JS 代码时,不仅会调用一个函数,而是会调用多个,也就会存在多个执行上下文,JS 引擎使用栈这种数据结构来管理这些执行上下文。
栈(stack)
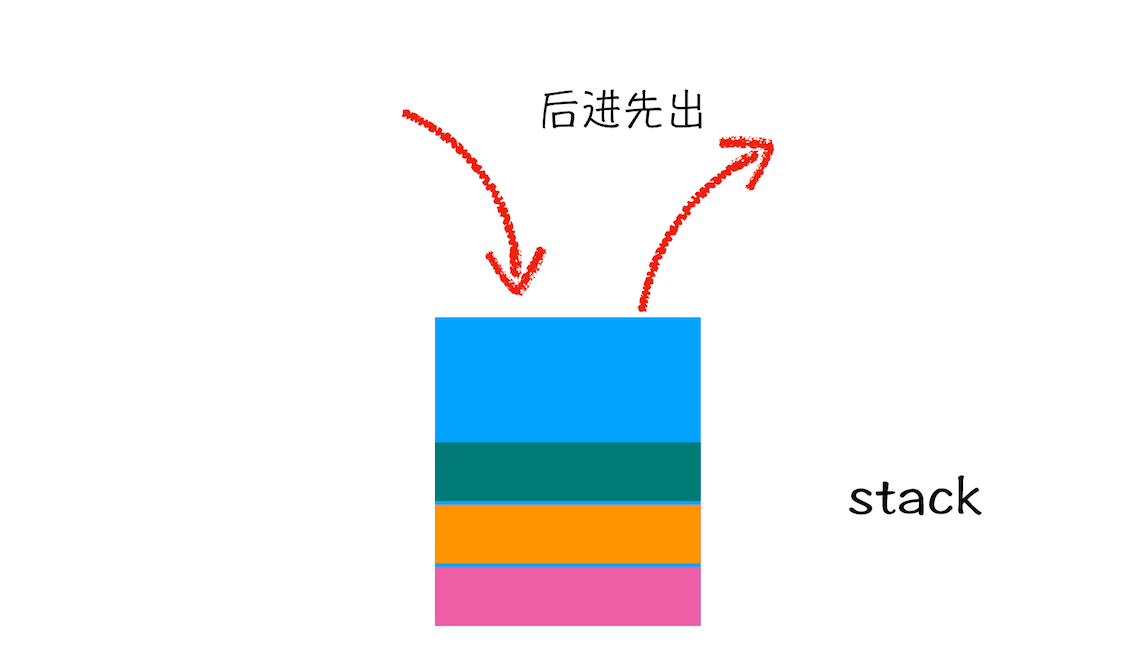
栈也称堆栈,是一种只能在一端进行插入和删除操作的特殊的线性表。按照先进后出的方式存储数据。先进入的数据被压入栈底,最后进入的数据在栈顶。读取时从栈顶开始弹出数据,最后一个进入的数据将最先被读取。说得形象一点就跟羽毛球筒一样,最开始筒是空的。往里面放羽毛球直至放满,拿出来的时候,最后放进去的羽毛球会最先拿出来。图来了:
JS 引擎利用栈来管理执行上下文。如下 JS 代码,这里定义了变量 a 和两个函数,最后调用了addAll()
1 | |
调用栈变化分析:
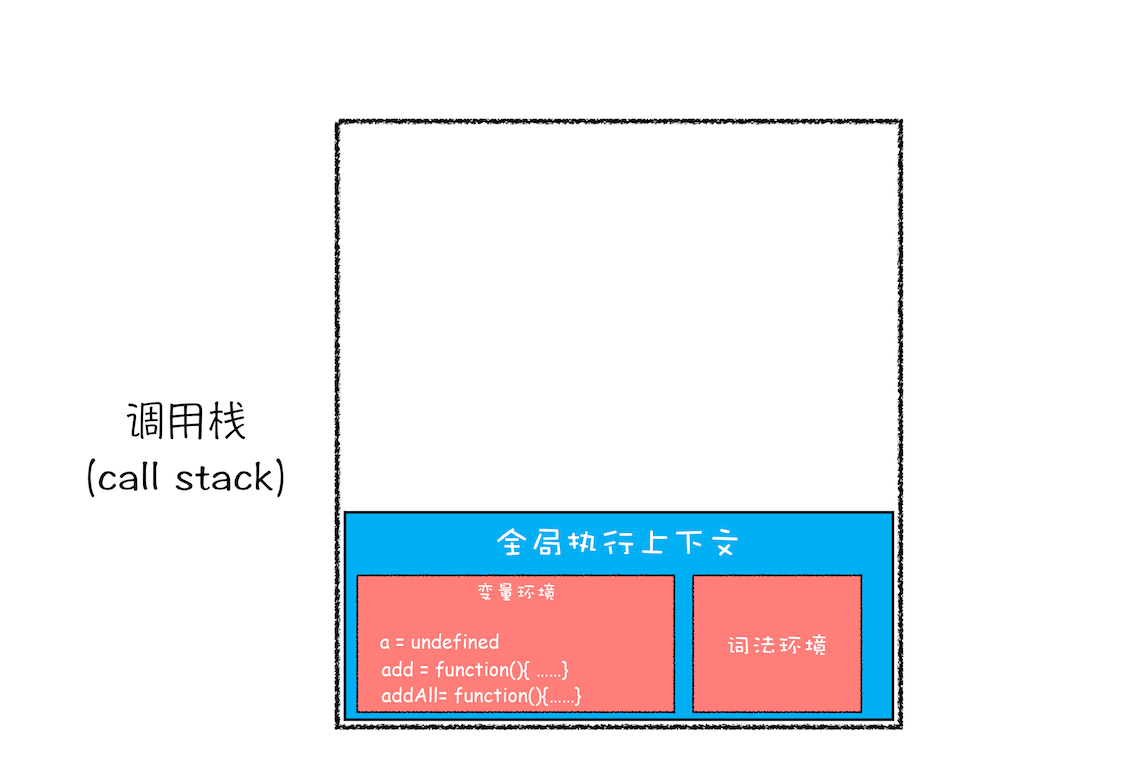
第一步: 编译全局代码,创建全局上下文,此时全局变量 a、函数的声明(add、addAll)都保存到全局上下文的变量环境中,全局上下文会被压入栈底。
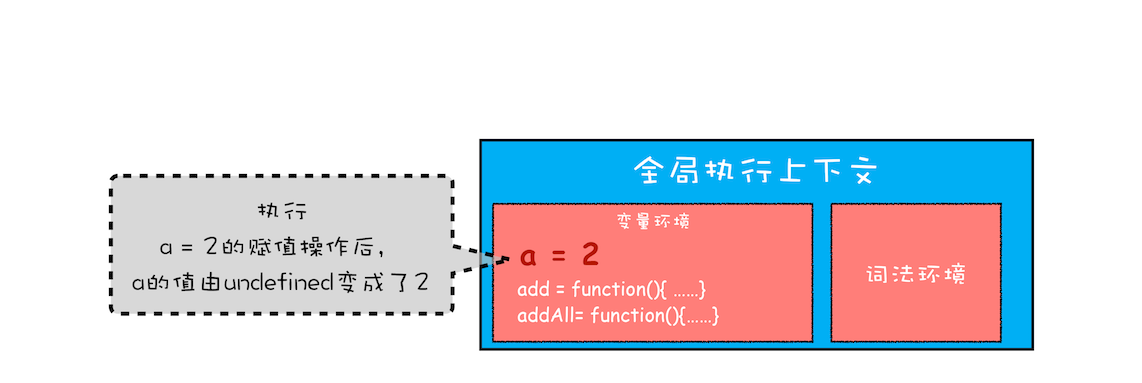
然后运行全局可执行代码,首先执行a = 2,那么全局变量环境中的 a 的值从undefined改为2
第二步: 执行完a=2的赋值操作后,就该执行addAll()了,这是一个函数调用,JS 引擎会编译该函数,并为其创建一个执行上下文,声明的变量 d 和 result 提升到顶部并赋值为undefined。该函数执行上下文会被继续压入调用栈中,如下图:

然后运行函数内的可执行代码,首先执行d=10,addAll函数执行上下文中的 d 的值由undefined变成了10。
第三步: 当执行到result=add(b,c),这里调用了add函数,同样继续为add函数创建执行上下文,并将其压入调用栈,此时的调用栈就有三个执行上下文:

add()函数执行完毕返回时,该函数的执行上下文就会从栈顶弹出,result 的值会设置为add函数的返回值,也就是 9

然后addAll执行到最后一行代码return a+result+d并返回,addAll的执行上下文也会从栈顶弹出,addAll函数的返回值就是最终的输出结果。此时的调用栈只剩下全局执行上下文。
至此,整个 JS 流程执行就结束了。调用栈是 JS 引擎追踪函数执行的机制,当一次有多个函数被调用时没通过调用栈就可以追踪到哪个函数在被执行以及各函数之间的调用关系。
在Chrome中,开发者工具里的 sources > Snippets 允许在浏览器的环境下运行一小段代码,在第三行处打上断点,运行该文件即可看到运行到断点时就暂停了,通过右边的调试可以继续查看运行情况,call stack处即可查看当前的调用栈情况
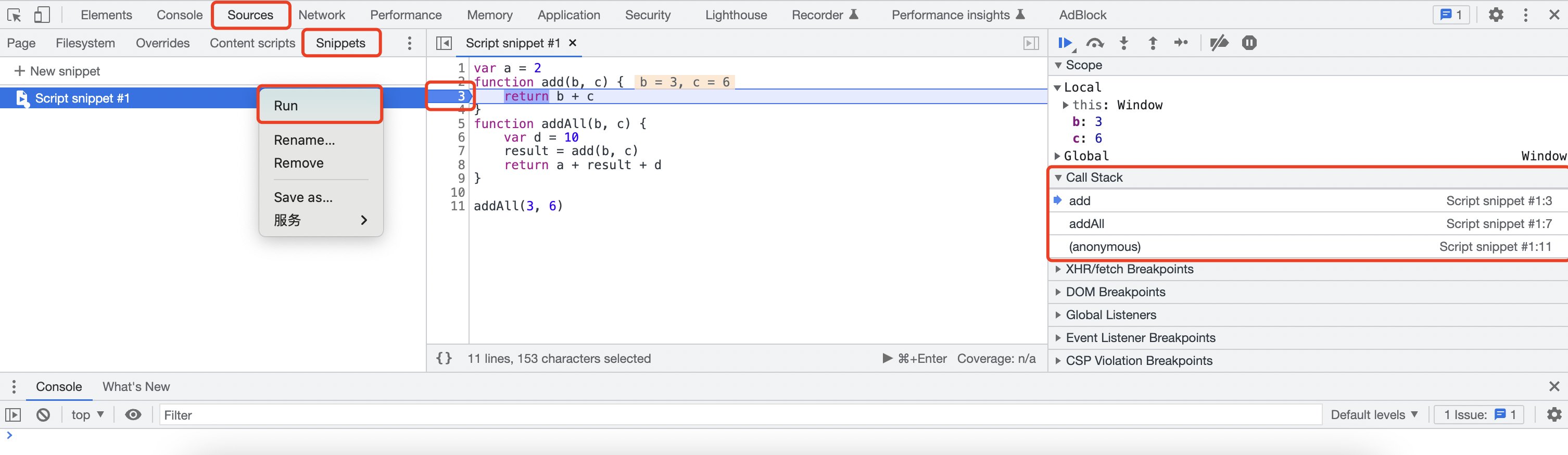
从右侧展示的信息来看,栈的最底部是anonymous,即全聚德函数入口,中间是addALl,最顶部是add函数,跟上面分析的是一样的。
栈溢出
栈是有大小的。当入栈的执行上下文超过一定数量,JS 引擎就会报错,如下运行的递归函数,这种错误就是栈溢出。
1 | |

尝试分析一下这段代码:
首先定义了一个 division 函数,JS 引擎创建函数执行上下文,压入栈中。然后执行里面的可执行代码,发现这个函数又调用了 division 函数,即递归调用。并且没有任何终止条件,那么它就会一直创建新的函数执行上下文,并且压入栈中,但调用栈容量有限制,超过最大数量后就会出现栈溢出的错误。
栈溢出的解决方案:
- 避免递归
- 使用定时器