大数据课程————MapReduce
MapReduce
一个分布式运算程序的编程框架,用户开发“基于Hadoop的数据分析应用”的核心框架。
优点:
- 易于编程,用户只关心业务逻辑,实现框架的接口
- 良好的扩展性。可动态增加服务器,解决计算资源不够的问题
- 高容错性。任意节点挂掉可以将任务转移至其他节点
- 适合海量数据计算。(TB/PB级别)几千台服务器共同计算
缺点:
- 不擅长实时计算。(mysql毫秒级别的)
- 不擅长流式计算
- 不擅长DAG有向无环图计算
MapReduce工作流程
- 运算程序一般分为2个阶段:Map阶段和Reduce阶段
- Map阶段并发MapTask并行运行,互不干扰;Reduce阶段的并发Reduce Task ,但他们的数据依赖于上一个MapTask并发实例的输出
- MapReduce编程模型只能包含一个Map和一个Reduce阶段,若业务繁杂,只能使用多个MapReduce程序串行运行
MapReduce进程
- MrAppmaster:整个程序的过程调度及协调
- MapTask:负责Map阶段的整个数据流处理
- ReduceTask:负责Reduce阶段的数据处理
编程规范
- Mapper阶段:继承Mapper类,输入输出均为kv形式,业务逻辑写在map()中,MapTask进程对每个kv仅调用一次
- Reduce阶段:继承Reduce类,输入为Mapper的输出数据类型,业务写在reduce()中,ReduceTask进程对每组k相同的kv调用一次reduce()
- Driver阶段:相当于Yarn的客户端,提交封装了MapReduce程序相关运行参数的Job对象到Yarn集群
本地Hadoop测试WordCount计算成功后,应将其提交到集群,交由集群计算。
- Driver类中输入输出参数填args[]数组的参数
- 根据实际情况添加依赖,打包后放入集群运行时,应填写全列名,如“com/yz/mapreduce/wordcount2/WordCountDriver”再添加其他参数即可运行
Hadoop序列化:java自带序列化的简化版
- 紧凑 :高效使用存储空间。
- 快速:读写数据的额外开销小。
- 互操作:支持多语言的交互
MapReduce的切片机制与MapTask并行度决定机制
数据块:HDFS上将数据分为多个块
数据切片:在逻辑上对输入进行分片,并不会在磁盘上对其切分成片存储,数据切片是MapReduce程序计算输入数据的单位,一个切片对应启动一个MapReduce
- 一个Job的Map阶段并行度由客户端在 提交Job时的切片数决定
- 默认情况下,切片大小=BlockSize
- 每个Slipt切片分配一个MapTask并行实例处理
- 切片时不考虑数据整体,而是逐个对单个文件单独切片
FileInputFormat切片分析:
-
程序找到数据存储的目录
-
遍历切片下的每个文件,切片时不考虑数据集整体,对每个文件单独切片
-
遍历第一个文件:
-
- 获取文件大小
- 根据切片公式计算切片大小,默认切片大小=blocksize
- 第一个切片0:128M,第二个128:256,第三个356:300M,每次切片都要判断切完剩下的部分是否大于块的1.1倍,不大于就划成一块切片(源码中有写)
- 将切片信息写入切片规划文件中
-
整个切片的核心过程都在getSplit( )中完成,InputSplit只记录了切片元数据
-
提交切片规划文件到YARN上,YARN的MrAppMaster根据切片规划文件计算开启MapTask的个数
获取切片信息API
- 获取切片名称:inputSplit.getPath().getName()
- 根据文件类型获取切片信息:(FileSplit)context.getInputSplit()
MapReduce框架
- 基本流程:

TextInputFormat:系统默认的切片机制
TextInputFormat是默认的FileInputFormat实现类。按行读取每条记录。键是存储该行在整个文件中的起始字节偏移量, LongWritable类型。值是这行的内容,不包括任何行终止符(换行符和回车符),Text类型。
CombineTextInputFormat切片机制
解决TextInputFormat对单个文件切片的缺陷,如果小文件过多将会产生大量MapTask,效率低下,CombineTextInputFormat将多个小文件从逻辑上划分给同一个MapTask,提高效率
虚拟存储切片最大值设置:CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
MapTask工作机制
- 读取数据组件Inputformat(接口,实际是TextinputFormat)通过getSplits方法对输入目录中的文件进行逻辑切片,得到block,有多少个block就有多少个MapTask
- 输入文件切块之后,由RecordReader对象(实际是LineRecordReader)进行行读取,读一行返回一个ky,key为首字母偏移量,value为这行的文本内容
- 读取block后返回ky,进入用户自己继承的Mapper类,重写map函数,写业务代码
- mapper结束后,通过conetxt.write收集结果,,在context中对其进行分区处理
- 然后会将数据写入内存,内存中这片区域叫环形缓冲区,作用是批量收集Mapper结果,减少磁盘IO的影响,ky对以及Partition的结果都会被写入缓冲区,写入之前ky都会被序列化成字节数组。缓冲区其实就是一个存放ky的数组,环形结构值一个抽象概念。缓冲区有100M大小,当当Mapper输出结果较多,则需要另起一个线程将数据写入磁盘,这个行为叫Spill溢写。溢写的阈值是80%,即当数组快到80%时,就开始溢写,同时还会接收Mapper数据,并且当二者速度相差过大时,内存还会等待溢写,直到可以继续收集。溢写之前对key的索引按照字典顺序进行快排,快排之后进行combiner规约,生成小文件。hadoop的mapred-site.xml中定义了缓冲区的相关设置。缓冲区大小通过mapreduce.task.io.sort.mb设置,阈值通过mapreduce.map.sort.split.percent设置
- 溢写程序启动后,对80M内容的Key做排序,排序是MapReduce模型默认的行为,是对序列化的字节做的排序
- 合并溢写文件,每次溢写都会在磁盘生成一个临时文件,多Mapper输出结果大,则会有多次溢写,有多个临时文件,整个数据处理结束后,开始对磁盘中的临时文件做Merge合并成一个文件,并写入磁盘,并为这个we你按提供一个索引文件,记录每个reduce对应数据的偏移
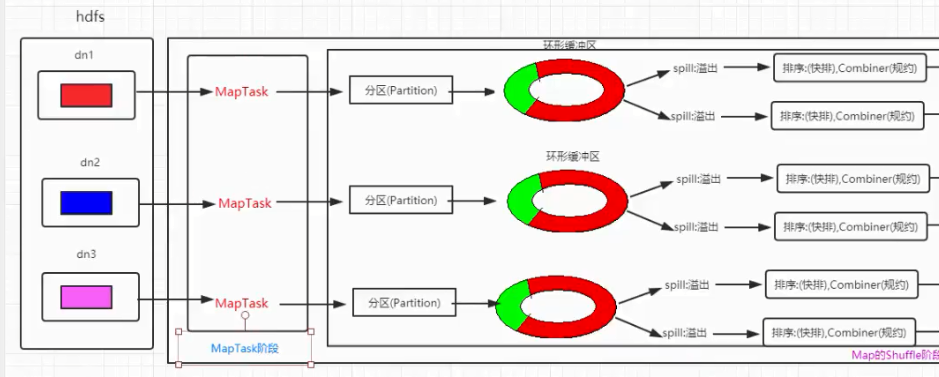

MapReduce工作流程
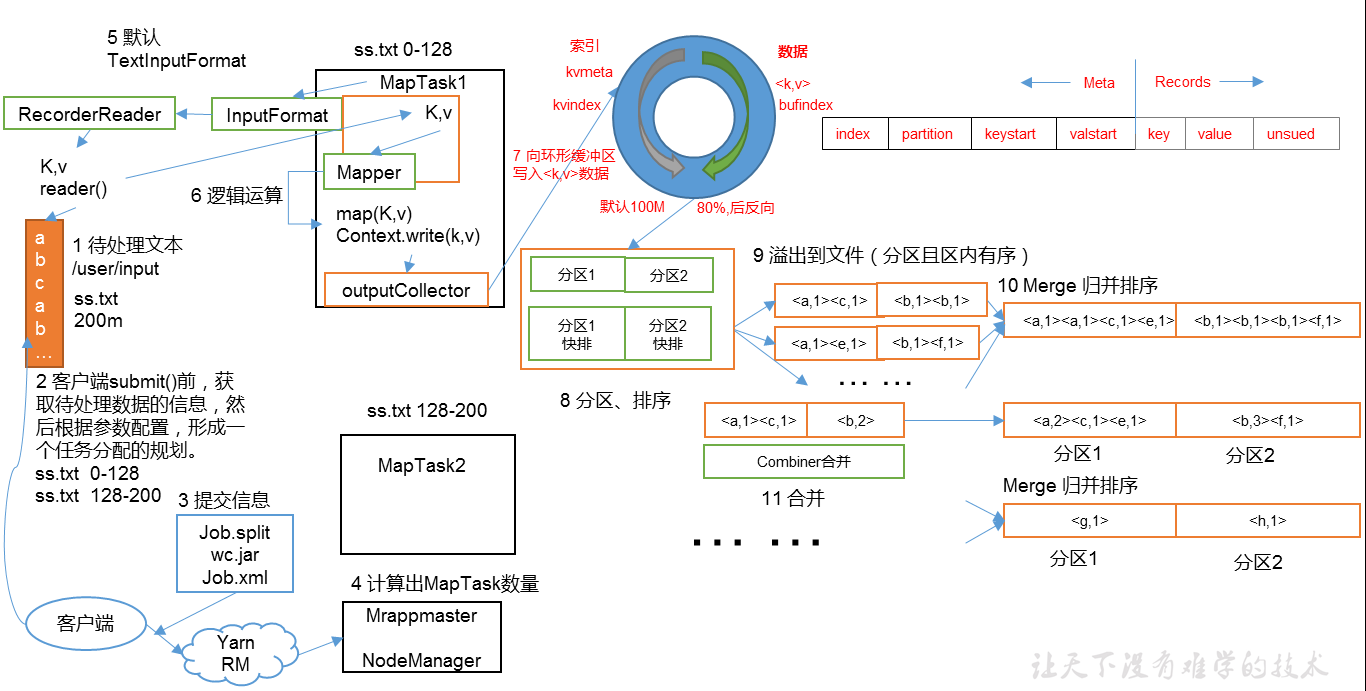

MapReduce_Shuffle机制
Map方法之后就开始Reduce阶段,Reduce第一个阶段是Reduce_Shuffle,一般当做Reduce业务层前置阶段。第二阶段即真正的ReduceTask,用来对数据进行操
Shuffle大致分为四个步骤:
- 分区:环型缓冲期前的逻辑分区
- 排序::缓冲期写入磁盘前的快速排序
- combiner规约:溢写前、合并小文件等都会用到的操作,可选
- 分组:小文件合并成一个大文件后,对其进行归并排序、分组


Partition分区
系统默认的分区逻辑如下,默认分区是根据key的hashCode对ReduceTask个数取模得到,用户无法控制key存储到哪个分区:
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
……
public int getPartition(K2 key, V2 value, int numReduceTasks) {
return (key.hashCode() & 2147483647) % numReduceTasks;
}
}
想要控制存储分区,可继承下面的Partitioner抽象类,并重写getPartitioner()方法:
public abstract class Partitioner<KEY, VALUE> {
public abstract int getPartition(KEY var1, VALUE var2, int var3);
}
若自定义了分区,必须在job驱动中设置自定义Partitioner,否则还是会走默认,并根据Partitioner的逻辑设置相应数量的ReduceTask
分区总结:
- 若ReduceTask数量>getPartitioner结果数量,则会产生空的part-r-000xx文件。造成资源浪费
- 若1<ReduceTask数量<getPartitioner结果数量,则一部分分区数据无法存放,报IO异常
- 若ReduceTask数量=1,则为默认情况,所有分区文件都交给一个ReduceTask,结果生成一个part文件
- 分区号必须从0开始,逐一累加
WritableComparable排序
排序是MapReduce中最重要的操作之一,MapTask和ReduceTask均会对数据排序,这是Hadoop行为,不论逻辑是否需要均会排序。
MapTask中,处理的结果暂时放在环形缓冲区,到达阈值后,对80%的数据进行一次快排,并将排序后的数据溢写到磁盘,全部处理完毕后对多有文件进行归并排序
ReduceTask中,从每个MapTask上远程拷贝相应的数据文件,若文件大于阈值则溢写到磁盘,否则存在内存中。
- 若内存中文件大小或数量到达阈值,则合并后将数据溢写在磁盘。
- 若磁盘中文件数量达到阈值则做一次归排生成一个大文件
- 所有数据拷贝完后,ReduceTask统一对内存和磁盘上所有数据进行一次归并排序
排序分类:
部分排序:MapReduce根据记录的键对数据集排序,保证输出的每个文件内部有序
全排序:最终输出结果只有一个文件,文件内部有序,一般不会使用这种方式,因为数据量太大,用一个ReduceTask处理效率太低
辅助排序:FroupingComparator分组,少用
二次排序(自定义排序):若compareTo中的判断条件为2个即为二次排序
Combiner合并
combiner是可选的步骤,是Mapper和Reduce之外的组件,Combiner的父类就是Reduce。Combiner的意义就是对每个MapTask的输出进行局部汇总,以减少网络传输量。
选择Combiner的限制条件是,使用后不能影响最终的业务逻辑,例如比较适合叠加操作,而不适合求平均值操作
outPutFormatgaishu概述
后续:
https://www.bilibili.com/video/BV1Qp4y1n7EN
P105