列表是动态的,长度大小不固定,可任意删减元素
元组是静态的,长度大小固定,无法增删,只能新建生成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 >>> ls=[1 ,2 ,3 ] >>> ls >>> ls.__sizeof__() >>> tup=1 ,2 ,3 >>> tup.__sizeof__() >>> >>> l=[] >>> l.__sizeof__() >>> tup=() >>> tup.__sizeof__()
列表与元组相同的3个元素,元组存储空间比列表少了16个字节。这16字节分别代表:
指向对应元素的指针。列表是动态的,需要存储指针
额外存储已分配的长度大小,用于追踪列表空间的使用情况,及时分配额外空间
1 2 3 4 5 6 7 8 9 10 11 12 13 >>> ls1=[] >>> ls1.append(1 ) >>> ls1.append(2 ) >>> ls1.append(3 ) >>> ls1 >>> ls >>> ls1.__sizeof__() >>> ls.__sizeof__() >>>
ls1初始化为空列表,追加至3个元素,ls初始化就是3个元素。初始化的3元素比追加的3元素小了8个字节。
列表追加的机制保证了列表的高效性,其增删操作的时间复杂度均为O(1)。如下是完整版本测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 l = [] __sizeof__ () 40 .append (1 )__sizeof__ () 72 .append (2 ) __sizeof__ ()72 .append (3 )__sizeof__ () 72 .append (4 )__sizeof__ () 72 .append (5 )__sizeof__ () 104
(确实会缩容)
TODO
初始化速度对比
1 2 3 4 5 6 7 8 ubuntu @VM-0 -7 -ubuntu:~$ python3 -m timeit 'x=(1 ,2 ,3 ,4 ,5 ,6 )'100000000 loops, best of 3 : 0 .0113 usec per loopubuntu @VM-0 -7 -ubuntu:~$ python3 -m timeit 'y=[1 ,2 ,3 ,4 ,5 ,6 ]'10000000 loops, best of 3 : 0 .0519 usec per loopimport timeitprint (timeit.Timer('x=[1 ,2 ,3 ,4 ,5 ]').timeit())
索引操作对比
1 2 3 4 ubuntu @VM-0 -7 -ubuntu:~$ python3 -m timeit -s 'x=[1 ,2 ,3 ,4 ,5 ,6 ]' 'y=x[3 ]'10000000 loops, best of 3 : 0 .022 usec per loopubuntu @VM-0 -7 -ubuntu:~$ python3 -m timeit -s 'x=(1 ,2 ,3 ,4 ,5 ,6 )' 'y=x[3 ]'10000000 loops, best of 3 : 0 .0232 usec per loop
元组比列表更加轻量级,性能速度略优于列表
列表不被使用时会被回收掉,未被使用且小的元组会被缓存至内存,性能优于列表
存储数据与数量不变,如返回地点经纬度,优先使用元组
存储数据获数量需要变动,如用户查看的帖子,优先使用列表
字典:键值对格式的元素集合。3.7后的字典有序,便于查、增、删
集合:与字典类似,没有键值对,无序唯一的元素组合,元素类型可不同
创建
注意:字典的key只能是不可变的,因此数字、字符串、元组均可作为key,但列表、字典不能作为key,因为是自动的
1 2 3 4 5 6 7 8 d1 = {'name' : 'jason' , 'age' : 20 , 'gender' : 'male' }d2 = dict({'name' : 'jason' , 'age' : 20 , 'gender' : 'male' })d3 = dict([('name' , 'jason' ), ('age' , 20 ), ('gender' , 'male' )])d4 = dict(name='jason' , age=20 , gender='male' ) s1 = {1 , 2 , 3 }s2 = set([1 , 2 , 3 ])
获取
1 2 3 4 5 print (dic[key])print (dic.get (key))print (v in s)
删除
1 2 3 4 5 6 pop (key)pop () pop ()
排序
1 2 3 4 5 sorted (d.items(), key=lambda x: x[0 ]) sorted (d.items(), key=lambda x: x[1 ]) sorted (s)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import timeid = [x for x in range (0 , 10000 )]for x in range (20000 , 30000 )]list (zip (id , price))def find_unique_price_using_list (products ):for _, price in products: if price not in unique_price_list: return len (unique_price_list)def find_unique_price_using_set (products ):set ()for _, price in products:return len (unique_price_set)print ('用时:{}' .format (end_list-start_list))500 倍):list 用时:0.5515346527099609 set 用时:0.0009975433349609375
同一性:二者均由哈希表实现
差异性:
字典存储哈希值、key、value 3种元素
集合只存哈希和元素
新增原理
1 2 3 4 5 6 'name' : 'mike' }'age' ]=18'a' }add ('b' )
向字典/集合(统称为哈希表)插入元素时,先计算出键的哈希值hash(key),再和mask = PyDicMinSize - 1 做与操作,计算出插入的位置:index = hash(key) & mask,计算位置后查看该位置是否为空:
若该位置为空则插入
若该位置已占用则比较哈希值和键是否相等:
哈希冲突会降低字典/集合操作的速度,因此哈希表内一般保留了1/3剩余空间,元素插入时剩余空间小于1/3时就会进行扩容,扩容时表内所有元素会被重新排放。
思考
在字典查找过程中,计算出的key的哈希值与已存在的hash值相等,但key值不相等?
解决:不同的key计算出来的hash相同,属于哈希冲突,在插入阶段就已经避免了这种错误
列表的可变和不可变问题。列表是内容可变,但它本身的地址是不变的,为什么不能用来当做字典的key,这里面是否混淆了什么?
(TODO)
这段没什么说的,简单带过。速通篇 也有简单介绍。
定义
前两者为了方便区分内容中的引号,第三种方便多行内容
转义
转义字符
说明
\
表示单引号\
\n
表示换行
\"表示双引号 "
字符串属于不可变序列,除了拼接方式以外,没有修改字符的方法。一般情况修改都是通过字符串切片或扫描原字符串,修改后放入新字符串。
+=拼接
当s1+=s2拼接字符串时,首先检测s1是否有其他引用,若没有则原地扩充字符串buffer大小,此方法时间复杂度为O(n),效率不算太低。
string.join拼接
将每个元素按照指定格式连接起来。如下,循环结束后列表中的元素为0~99999,通过空格连接所有元素,并赋值给 l
1 2 3 4 l = [] for n in range (0 , 100000 ):.append (str (n))' ' .join (l)
其他操作函数
分割:string.split()常用于路径、链接等切割子串的场景
去首尾:string.strip(str)
此处没什么说的,速通篇的文件操作内容基本都有。比较常用的应该是Json相关的一些函数,这里再次重申一遍。
dump、load和dumps、loads
dump、load
dump用于将一个对象存储至本地文件
load用于从本地文件中读取内容字符串并转为对象
dumps、loads
dumps用于将一个对象转为字符串
loads用于将字符串转回对象
注意,在实际环境中,IO的应用场景较多适用于文件读写、网络、其他进程等方面。如下使用NLP分析文本的任务用到了多方面的东西。
文本 in.txt 内容
1 2 3 4 5 6 7 8 9 I have a dream that my four little children will one day live in a nation where they will not be judged by the color of their skin but by the content of their character . I have a dream today.that one day down in Alabama, with its vicious racists, . . . one day right there in Alabama little black boys and black girls will be able to join hands with little white boys and white girls as sisters and brothers. I have a dream today.that one day every valley shall be exalted, every hill and mountain shall be made low, the rough places will be made plain, and the crooked places will be made straight, and the glory of the Lord shall be revealed, and all flesh shall see it together.is our hope. . . With this faith we will be able to hew out of the mountain of despair a stone of hope. With this faith we will be able to transform the jangling discords of our nation into a beautiful symphony of brotherhood. With this faith we will be able to work together, to pray together, to struggle together, to go to jail together, to stand up for freedom together, knowing that we will be free one day . . . .and when we allow freedom ring, when we let it ring from every village and every hamlet, from every state and every city, we will be able to speed up that day when all of God's children, black men and white men, Jews and Gentiles, Protestants and Catholics, will be able to join hands and sing in the words of the old Negro spiritual: "Free at last! Free at last! Thank God Almighty, we are free at last!"
文本分析:该文本包含多段,每段包含大小写字母、标点符号、空格、换行等
任务:计算该文本中每个单词出现的频次,按频次高低排列出来并输出到 out.txt
处理代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import redef parse (text ):r"[^\w]" , " " , text)' ' )filter (lambda text: text != '' , text)for word in text_list:if word not in word_cnt:0 1 sorted (word_cnt.items(), key=lambda kv: kv[1 ], reverse=True )return sorted_dicwith open ("in.txt" , "r" ) as f:with open ("out.txt" , "w" ) as f:for word, cnt in word_cnt:f'{word} {cnt} \n' )
注意,这里的 parse 函数课分析任意文本数据,但如果文件过大可能会造成内存崩溃。通过给read指定 size 参数或者通过 readline() 来读取少部分文本,减轻内存压力
该代码用到的一些知识点:
re.sub(r"[^\w]", " ", text):提取所需文本
**(TODO)**这里有个问题:为什么正则用的是\w,匹配所有字母数字下划线,替换成空格。那不是代表匹配到的这些字母数字下划线将替换成空格吗?但替换的结果却是将符号替换成了空格,这不是反了吗?
操作IO应该注意的点
应进行充分的错误处理,细心编码防止出现漏洞
对内存、磁盘占用有充分估计
代码简介清晰,充分利用JSON序列化
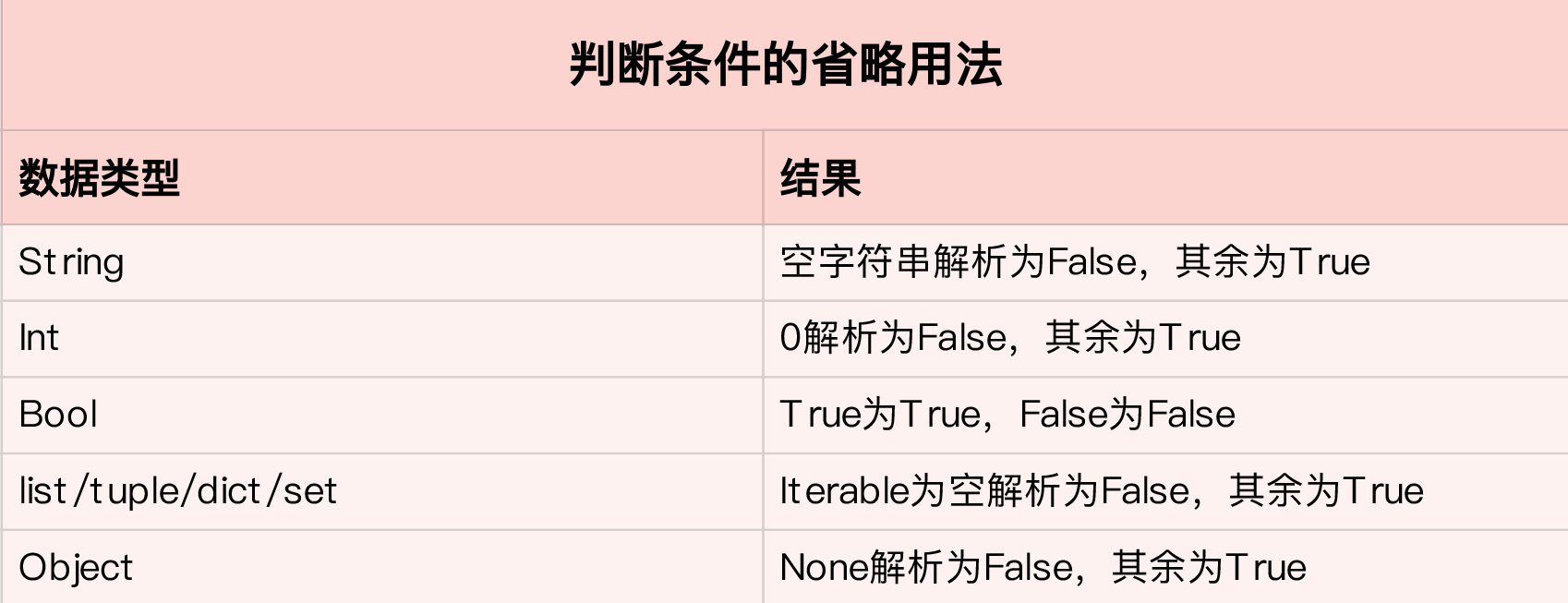
if语句可单独使用,但elif、else必须配合if使用。
if省略判断语句的写法 、
除了boolean外,不建议写成省略方式
只要对象的数据结构是可迭代的,均可以使用for item in <iterable>: ……的方式遍历序列中的所有元素。如需在遍历时获取当前循环的索引,可使用内置enumerate() 函数遍历集合,这个函数返回序列的值和对应的索引
1 2 3 4 l = [1 , 2 , 3 , 4 , 5 , 6 , 7 ]for index , item in enumerate(l):if index < 5 :print (item)
关于for循环与while循环的选用:
(在效率上,for循环可能更优于while循环)
很多人写for循环都爱这样写,在没学会之前看这种复用代码是很头疼的,全靠猜。但写的人会觉得很简洁,一行代码搞定,效率upup。如下是一些常见的复用情况
if、for复用
1 2 3 4 5 6 7 8 9 10 for item in iterable if conditionfor item in iterable:if condetion:for s in text .split (',' ) if len (s.strip()) > 3
if、else、for复用
1 2 3 4 5 6 7 8 9 if condition else expression2 for item in iterablefor item in iterable:if condition:else :
if 、for双循环
1 2 3 4 5 for item1 in iterable for item2 in iterable if conditionfor xx in x for yy in y if xx != yy
举例:将下列属性分别压成一个装了3个字典的列表
1 2 3 4 5 attributes = ['name' , 'dob' , 'gender' ]values = [['jason' , '2000-01-01' , 'male' ],'mike' , '1999-01-01' , 'male' ],'nancy' , '2001-02-01' , 'female' ]]list = [dict(zip(attributes, value)) for value in values]
关于函数定义
def 是可执行语句,函数在调用前是不存在的。因此在调用时需要确保所需函数已经定义过。
关于传参
参数可设默认,调用时没传时使用默认,传了就用传入的
参数可以是任意类型,只要符合代码、语法规则即可(多态)。使用时可以再函数开头添加数据类型检查
1 2 3 4 5 6 def f1 (): print ('hello' ) def f2 (): print ('world' ) f2 ()f1 ()
嵌套的优点
保护内部函数隐私,不会暴露在全局作用域,如函数内部有隐私数据等情况,就可以使用嵌套,外部无法单独调用到它的内部函数
合理的嵌套有利于提高代码运行效率,当内部函数需递归或多次运行时,只需运行一次的外部函数可以执行某些不必要的其他操作。如下:
递归计算阶乘,执行循环计算的主体是内部函数,外层函数用于检测输入合法性
1 2 3 4 5 6 7 8 9 10 11 12 13 def factorial (input if not isinstance (input , int ):raise Exception('input must be an integer.' )if input < 0 :raise Exception('input must be greater or equal to 0' )def inner_factorial (input if input <= 1 :return 1 return input * inner_factorial(input -1 )return inner_factorial(input )print (factorial(5 ))
全局变量:定义在整个文件层次上,任意地方均可访问
局部变量:只在函数内部有效,函数执行完毕后变量被回收。
如局部变量与全局变量同名,则局部变量生效
注意
不能再函数内部随意改变全局变量的值,Python解释器默认函数内部的变量为局部变量,又发现它在内部并未声明,就无法操作变量。
变量的二次声明
如需在函数内部修改全局变量的值,在函数内部使用global重新声明该变量
如需在嵌套函数的内部函数中修改外部函数定义的变量,则需要在内部函数内部使用nonlocal重新声明该变量
定义:闭包也称闭合函数。在闭合函数中,内部函数对外部作用域的变量进行引用 ,并且一般外部函数的返回值为内部函数 ,那么内部函数就被认为是闭包。
例如:
这里的nth_power()的返回值是exponent_of,并不是表达式或具体的数值。
并且square = nth_power(2)执行完后,2这个参数作为exponent仍然会被记住,相当于提前传入了这个参数进去。再次使用aquare(2)的时候,这里的2传给了内部函数定义的base,这样就可以输出结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def nth_power (exponent ):def exponent_of (base ):return base ** exponentreturn exponent_of 2 ) 3 ) locals >.exponent(base)>locals >.exponent(base)>print (square(2 )) print (cube(2 )) print (nth_power(2 )(8 ))
格式
1 lambda
例子
1 2 3 4 5 6 7 8 square = lambda x: x**2 square (3 )square (x):return x**2 square (3 )
匿名函数与常规函数的区别
lambda是一个表达式,并不是语句
常规函数需要通过函数名调用,且必须先定义。但作为表达式的lambda无需名字即可使用,因此lambda可以用在常规函数不能用的地方。
如列表内:[(lambda x: x*x)(x) for x in range(10)]
如作为函数的参数:ls.sort(key=lambda x: x[1])
lambda主体只有一行简单表达式,无法扩展成多行代码块
Python设计之初就是为了让lambda专注于简单任务,常规函数负责复杂的多行逻辑。
匿名函数的优点
使用场景:你需要一个简短的函数,且只会在程序中调用一次
优势:简化代码复杂度,提高代码的可读性,符合Python编程习惯
1 2 3 4 5 6 7 def square (x ):return x**2 map (square, [1 , 2 , 3 , 4 , 5 ])map (lambda x: x**2 ,[1 , 2 , 3 , 4 , 5 ])
(Python支持多种编程范式:过程式、面向对象编程、函数式编程)
函数式编程指代码中每一块都是不可变的,由纯函数的形式组成。即函数本身互相独立,互不影响。对于相同的输入,总会有相同的输出。例如:一个列表作为参数传递至函数内,函数返回结果后原列表不会变化。
函数式编程优缺点
不可变特性使得程序更加健壮、易于调试
限制较多,比较难写
例子
1 2 3 4 5 6 7 8 9 10 11 12 def multiply_2 (l ):for index in range (0 , len (l)):2 return ldef multiply_2_pure (l ):for item in l:2 )return new_list
Python内置的几个相关函数
map()
返回一个将 function 应用于 iterable 中每一项并输出其结果的迭代器。即对于每一个序列中的元素,都运行function这个函数,最后返回一个迭代器。
如下,对列表中每个元素乘以2操作
1 2 ls = [1 , 2 , 3 , 4 , 5 ]new_list = map(lambda x: x * 2 , ls)
检测运行时间可得map()是最快的,由于map()由C语言写的,无需通过Python解释器间接调用,且内部做了诸多优化,因此运行最快。
1 2 3 4 5 6 7 8 python3 -mtimeit -s'xs =range (1000000 )' ' map(lambda x: x*2 , xs)'2000000 loops, best of 5 : 171 nsec per loop 'xs =range (1000000 )' ' [x * 2 for x in xs]'5 loops, best of 5 : 62.9 msec per loop 'xs =range (1000000 )' ' l = []' ' for i in xs: l.append(i * 2 )'5 loops, best of 5 : 92.7 msec per loop
filter()
用 iterable 中函数 function 返回真的那些元素,构建一个新的迭代器。即对序列中每个元素,都是用function判断,并返回True或False,最后量返回True的元素组成一个新的迭代器。
例如获取列表中的偶数
1 2 3 l = [1 , 2 , 3 , 4 , 5 ]new_list = filter(lambda x: x % 2 == 0 , l)
reduce()
reduce()函数在functools模块中导入。reduce()将两个参数的 function 从左至右积累地应用到 iterable 的条目,以便将该可迭代对象缩减为单一的值。即对序列中每个元素以及上一次调用后的结果,运用function进行计算,最后返回一个单独的数值。
例如计算某列表内所有元素的乘积,就是计算:((((1*2)*3)*4)*5)的值
1 2 3 ls = [1 , 2 , 3 , 4 , 5 ]product = reduce(lambda x, y: x * y, ls)
sorted()
根据 iterable 中的项返回一个新的已排序列表。具有两个可选参数,它们都必须指定为关键字参数。
key 指定带有单个参数的函数,用于从 iterable 的每个元素中提取用于比较的键 (例如 key=str.lower)。 默认值为 None (直接比较元素)。reverse 为一个布尔值。 如果设为 True,则每个列表元素将按反向顺序比较进行排序。
key形参的值一般是一个函数或其他可调用对象,在进行比较前,每个列表元素调用该函数(或可调用对象)。如下,按照字典的value值进行排序。d.items()拿到的是键值对,lambda匿名函数返回键值对的value值,sorted按照value 值进行排序。
1 sorted (d.items() [1] )
默认情况下,对字符串排序时是按照ASCII的大小比较的。
timeit模块是内置用于统计小段代码执行时间的模块,该库默认将语句执行一百万次,并从提供从集合中花费的最短时间。
官网地址:https://docs.python.org/zh-cn/3.8/library/timeit.html
语法
1 2 3 4 5 number )
调用方式
命令行调用
1 2 3 4 python3 -m timeit '"-" .join (str(n) for n in range (100 ))'range (1000000 )' 'map (lambda x: x*2 , xs)'
函数接口调用
1 2 3 4 5 import timeit>>> timeit.timeit('"-".join(str(n) for n in range(100))' , number=10000 )>>> timeit.timeit(lambda : "-" .join(map (str , range (100 ))), number=10000 )
类:对应class,是一群有着相同属性和函数的对象的集合。
对象:class实例化生成的东西
属性:对象的静态特征,如一个人的身高、年龄
函数:对象的某个动态能力
类,属性,函数,对象的关系可以总结为:类是一群具有相同属性和函数的对象的集合 。
面向对象的一大优势就是将算法的复杂性隔离开,保留街口和其他代码不变。在公司团队协作中,设计好合理分层后,每层的逻辑只需要处理好分内的事即可。
类常量
1 2 3 4 5
类函数
在函数上方添加@classmethod装饰器。类函数第一个参数一般是cls,表示必须传一个类进来。
最常用的功能是实现不同的init构造函数。
成员函数
最常用的函数,无需任何装饰器生命,第一个参数为self,代表当前对象的引用。
常用古语查询、修改类的属性等
静态函数
在函数上方添加@staticmethod装饰器
用于做一些简单独立的任务,便于测试、优化代码结构。
面向对象学过的话这个应该很简单就能理解。子类拥有父类的特征(函数、属性),也可以拥有自己不同的特征。大概包括以下三个内容:
继承:继承父类属性&函数。
重写:子类重写父类函数,补充细节代码。
新特征:子类可以定义新函数、属性。
构造函数
子类生成对象时,不会自动调用父类的构造函数。如果想在子类调用父类的构造函数,必须使用super关键字或类名显式地调用。
子类需要自动调用父类构造:子类不重写__init__()函数,隐式调用父类构造
这种情况下,子类调用继承的函数时,是通过父类对象调用的,并非通过子类本身调用
子类不需要自动调用父类构造:子类重写__init__()函数
这种情况下,子类只继承父类的成员函数,不继承构造函数中的私有属性
子类既需重写__init__()又需调用父类构造:在子类构造函数中使用super()显式调用父类构造
???关于子类调用父类成员函数时到底是通过哪个对象调用的,做个试验观察一下
如下案例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Document (Entity):def __init__ (self , object_type'document class init called' )self , 'document' )self .object_type = object_typedef get_context_length (self 'get_context_length not implemented' )def print_title (self self .title)
访问父类变量的方式
调用父类中可以访问到本身私有变量的函数
不推荐的写法,强行访问:self._ParentClass__var
多继承
多继承又分为两种:一个类同时继承多个类或者一个类单一继承多个类(广度与深度)
单一继承时,构造执行顺序为子类-> 父类 -> 爷类 ->… 的链式关系
多重继承(例如菱形继承)时:基于某算法进行查找,可自己查询:className.__mro__
1 2 >>> bc.Document.__mro__ class 'bc.Document' >, <class 'bc.Entity' >, <class 'object' >)
多重继承的构造方法
如下,这是一个搜索引擎缓存类,继承了搜索引擎类和缓存模块,这里有一些复杂而又经典的调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class BOWInvertedIndexEngineWithCache (BOWInvertedIndexEngine, LRUCache):def __init__ (self super (BOWInvertedIndexEngineWithCache, self ).__init__()self )def search (self , queryif self .has(query):'cache hit!' )return self .get(query)super (BOWInvertedIndexEngineWithCache, self ).search(query)self .set(query, result)return result
多重构造下有两种方式初始化父类
初始化该类的第一个父类(python2写法):super(BOWInvertedIndexEngineWithCache, self).__init__()
传统方式(python3写法): LRUCache.__init__(self)
补充知识:
检索算法:倒排索引
一般来说,如果真的需要Entity类不让外界实例化,那就直接把Entity做成抽象类。抽象类使用abstractmethod 装饰器来表示,抽象类只能作为父类存在,无法实例化,抽象类中的函数就是抽象函数。子类继承抽象类,必须重写所有抽象函数。
Java中也有抽象类的语法。抽象类是自上而下的设计风格,类似于接口,用简单的代码定义好规则,然后交给不同的开发人员去开发和对接。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from abc import ABCMeta , abstractmethodclass Entity (metaclass=ABCMeta )@abstractmethod def get_title @abstractmethod def set_title Entity ()Traceback (most recent call last):File "<stdin>" , line 1 , in <module>TypeError : Can 't instantiate abstract class Entity with abstract methods get_title , set_title
在导包时,需要在模块所在的文件夹新建一个 __init__.py,内容可以为空,也可以用来表述包对外暴露的模块接口。不过事实上这是 Python 2 的规范。在 Python 3 规范中,__init__.py 并不是必须的,
在导包时应注意代码的顺序。代码是由上至下逐行运行的。编辑器在保存时有可能会重新对导包进行排序,从而导致包导入失败。
同路径引用
1 2 3 4 5 6 7 8 9 10 .from utils import get_sumfrom class_utils import *
不同路径引用
注意,类似PyChrome编辑器会将sys.path[0]也就是路径列表的第一项设置为项目根目录的绝对地址,所以sys.path.append("..")是可以正常导入的。但我这里的sys.path[0]是当前模块所在目录,所以无法导入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 .import sys".." )0 ]+'\\..' )'d:\\xxx\\xxx\\xxx\\modo' )from utils.class_utils import *from sub.sub_ff import *
在大型工程中尽可能使用绝对位置。对于独立项目来说,所有模块的追寻方式最好从项目的根目录开始追溯,这叫相对的绝对路径。
上面我已经写了如何导入上一层目录下的模块/指定目录模块,其实质就是将当前路径目录中的路径修改成想要的路径,或者直接在列表中添加新的绝对路径。但这并不是最佳方案,是不推荐的写法。最佳写法应该是为该项目设置虚拟环境,并讲根目录以环境变量的方式添加进去。
1 2 3 4 5 6 7 8 9 10 11 12 13 /path/ to/new/ virtual/environment /bin/ activate
注意用法 :if __name__=='__main__'
__name__属性是Python的一个内置属性,记录了一个字符串
1 2 3 4 5 6 7 8 # utils.py 在本文件中调用时,显示__main__ __name__ )# out: __main__ # main.py 在其他文件中调用utils.__name__ 时,显示的是utils模块名称 __name__ )# out: utils
这个判断表示当__name__的值为__main__时,才能执行块中的代码,如果不是则不执行。
Python的import导入其他模块时会自动将暴露在外面的代码全部执行一遍。因此如果需要把某个文件封装成模块以供其他模块调用,就必须将要执行的代码放在if __name__=='__main__':块下面。
1 2 3 4 5 6 7 8 def get_sum (a, b ):return a + bif __name__ == '__main__' :print ('testing' )print ('{} + {} = {}' .format (1 , 2 , get_sum(1 , 2 )))
总结来说就是
import文件内的if __name__=='__main__':不会执行
主程序内的代码if __name__=='__main__':会执行