阿里大数据架构导论
离线任务
两大日志采集系统:
- Webim: Aplus.js
- Appim: User Track
不同场景下的埋点规范打通多种业务场景:通过TimeTunel实现高性能、高可靠性的数据传输体系等。
日志采集
浏览器页面日志采集
- 页面展现日志
- UV:页面访客数量
- PV:页面浏览量
收集流程:
-
采集:采集脚本植入HTML的JS脚本中,浏览器解析后脚本执行,收集各类信息。
-
发送:脚本采集到信息后,将发送至日志服务品
-
收集:日志服务器接收后,写入日志缓冲区
-
解析:服务端日志解析
-
页面交互日志
收集鼠标或輸入焦点移动变化或者对页面交互的反应等,采用黄金令箭解决方案。
收集流程:
- 业务方注册需采集的交互日志/业务场景以及采集点
- 业务方将日志采集代码植入页面,将代码与交互行为绑定
- 用户产生行为时,正常业务与采集代码—起被触发执行
- 采集完成后将日志传回服务器
3.日志的清洗与预处理
将识别流量攻击/网络爬虫/虚假流量的日志剔除、型数据库装载使用。
App端日志采集
通过UserTrack的SDK来进行无线日志的收集。UT将不同的用户行为分成几个类型:
页面事件
记录信息:
- 设备及用户基本信息
- 被访问页面信息(业务参数)
- 访问基本路径(页面来源等)
基本方法:
• 页面展现调用接口
• 页面退出调用接口
• 添加页面扩展信息接口
控件点击事件
日志统一
統一的原因:纯本地App和H5 App互相跳转,导致用户路径、数据丢失严重。统一有利于数据统计、数据采集采用Native部署采集SDK,将H5日志归到Native日志中
- 采集SDK可以采集到更多设备相关数据
- 采集SDK处理日志时会先在本地缓存,再借机上传
无线客户端日志传输
概括:日志产生后,先存储在客户端本地,在伺机上传。(需考虑前台操作时间、日志大小及合理性等)
日志上传时向服务器发送POST请求,服务端收到后对日志进行校验、存储、甚至按时间分流。日志收集后,通过消息队列Timel将日志给到MaxCompute,提供给下游实时订阅、实时计算或者离线计算。
数据同步
数据同步即将数据源的数据同步到目标库的过程。
源数据的来源和分类如下:
- Mysgl, Oracle等结构化数据
- HBase、MongoDb等非结构化数据
- OSS、NAS等文件结构
同步方式
直连同步:通过规范接口(JDBC等)直接连接业务库。配置、实现简单,适合操作性业务系统的数据同步,但对源系统的性能影响较大,抽取方式本身性能也较差。不适合从业务系统到数据仓库系統的同步
数据文件同步:通过约定好的文件编码、大小格式等,从源系统生成数据的文本文件,由专门的FTP服务器传输到目标系统后加载到目标库。适合数据源包含多个异构数据库系统;文件传输前对数据压缩加密、传输中时校验文件的数据量以及文件大小,保证文件传输的效率和安全性。
数据库日志解折同步:通过使用日志文件进行系统恢复。如Oracle通过源系統进程,读取归档日志用于收集变化的数据信息。通过判断日志中的变更是否属于被收集对象,将其解析置目标数据文件中,通过网络传输至目标系统,加载导入至目标库。
此实现方式基于实时与准实时之间,延迟在毫秒级别。对业务系统性能影响较小。缺点:
- 数据延迟:业务系統做批量补录时可能使数据更新量超过系統处理峰值,导致数据延迟
- 投入较大:需在源库与目标库之间部署一个系统实时抽取数据
- 数据漂移和遗漏:对增量表而言,指前长天和后一天之间凌晨附近的数据丢失。
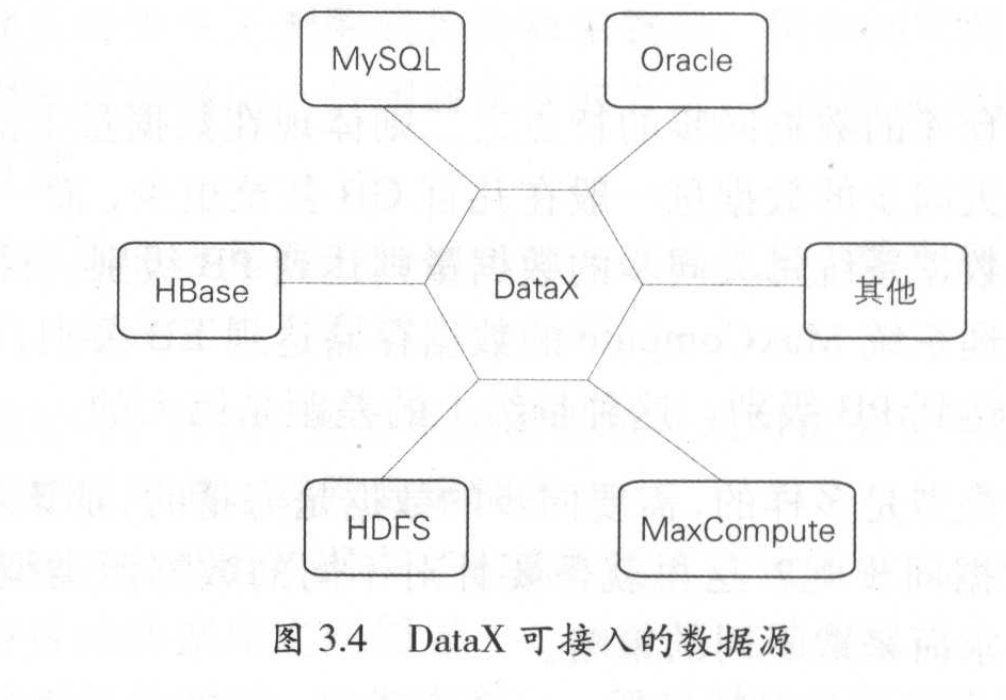
阿里DataX的数据仓库
集成性:集成了不同的数据来源、不同形式的数据将其整合到一起。除了数据库内的结构化数据,还有诸如日志、图片、视频等大量非结构化数据。
数据量:传統数据库的同步量大约在几百GB,阿里的MaxCompute在EB级别,每日同步量也是PB级。
DataX 将数据从数据源读出后,转换为中间态。并在目标数据库系统将中间态数据转为对应的数据格式写入。
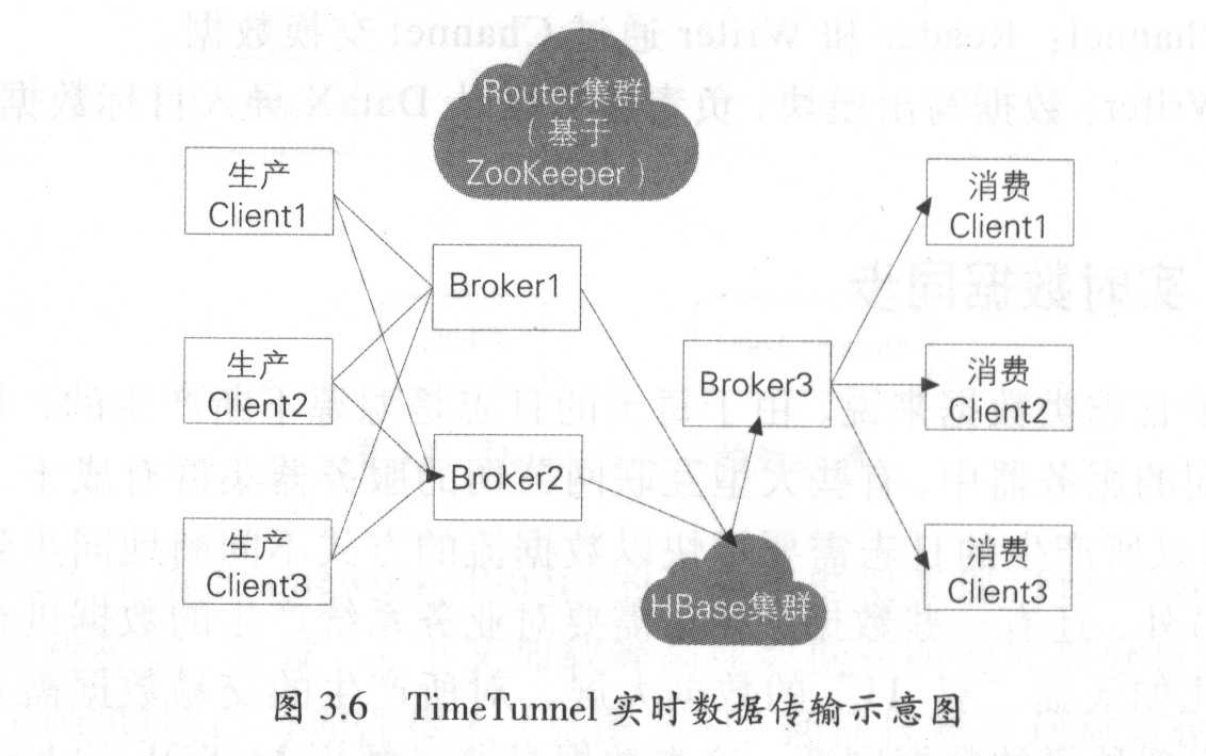
TimeTunnel实时数据传输平台
基于生产者、消费者和Topic消息标识的消息中间件,将消息持久化到HBase的高可用、分布式数据交互系统。(类似Kafk)
数据计算
计算云平台:
- 离线计算平台MaxCompute:自主研发的离线大数据平台,功能丰富、存储/计算能力强大
- 实时计算平台StreamCompute:自主研发的流式大数据平台,较好支持流式计算
- 数据鏊合及管理体系OneData:数据整合及管理的方法体系和工具
MaxCompute
主要用于海量数据的存储和计算,提供完善的数据导入方案、以及多种经典的分布式计算模型。采用抽象的作业处理框架,将不同场景的各种计算任务统一在同一平台上。为不同用户需求的各种数据处理任务提供统一的编程接口和界面。

组成
客户端:以Web、SDK、CLT、IDE等方式对外提供服务与实现。
接入层:提供HTTP服务、Cache、负载均衡,实现用户认证和服务层面的访问控制。
逻辑层:核心部分,实现用户空间和对象的管理,命令的解析与执行逻辑、数据对象的访问控制与授权等。有三个角色:
- Worker:处理所有RESTful请求,对于需要启动MapReduce的作业,生成MaxCompute Instance提交给Schedule进一步处理。
- Schedule:负责MaxCompute Ingtance的调度和拆解,并向计算层的计算集群询问资源占用情况以进行流控。
- Excutor:负责MaxCompute INstance的执行,向计算层的计算集群提交真正的计算任务
计算层:飞天内核,运行在和控制层相互独立的计算集群上,包括Pangu、Fuxi. Nuwa/ZK、Shennong等MaxConpute中的元数据存储在阿里云计算的另一个开放OTS中,元教据內容主要包括用户空间元数据、Table/Partition Schema、ACL、Job元数据等。
特点
计算性能高且普患;集群规模大且稳定;功能组件强大;安全性高
统一开发平台
围绕MaxCompute计算平台,从任务开发、调试、测试、发布、监控、报警到运维管理,一整套工具和产品。

在云端D2
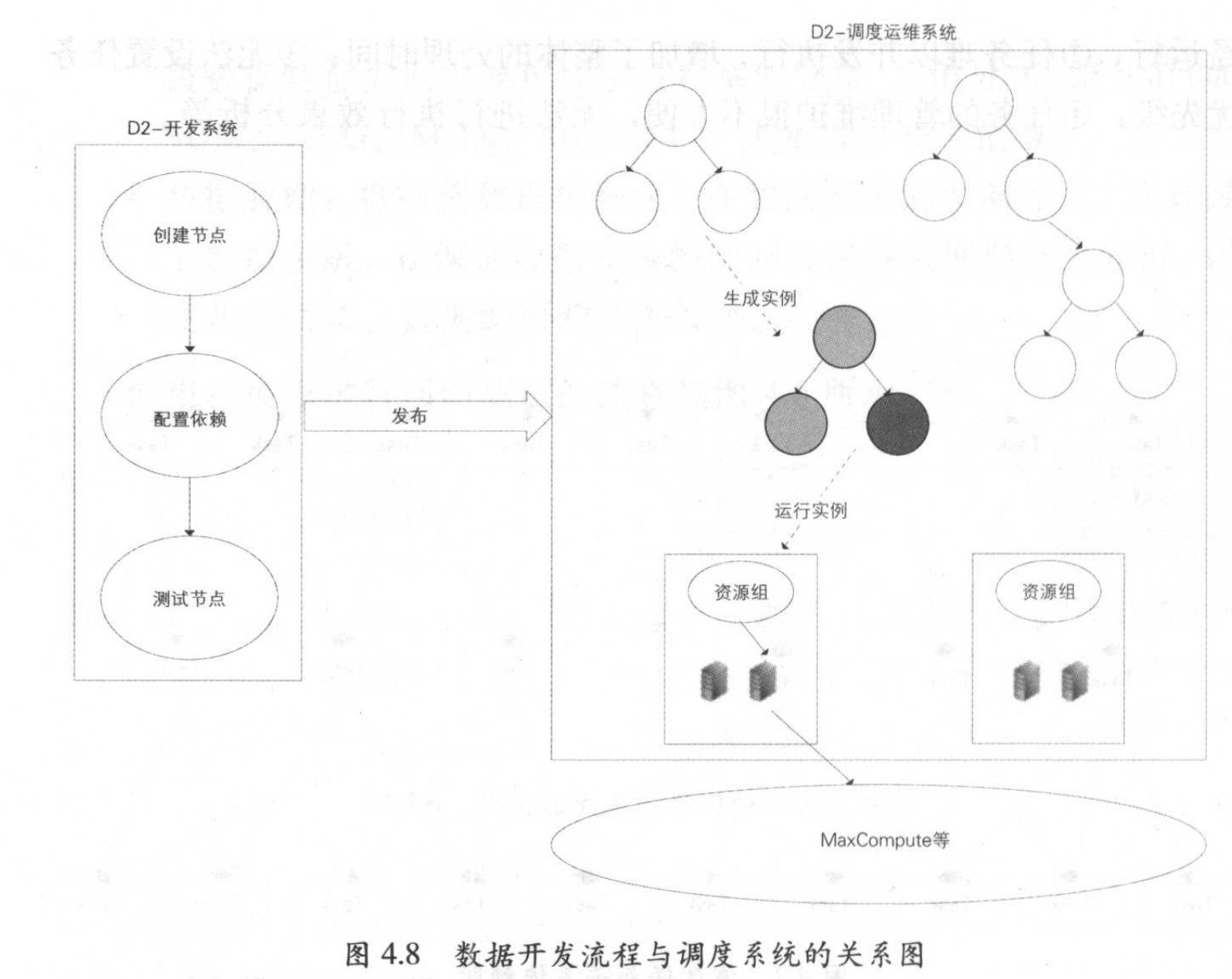
数据开发平台,集开发、调试、发布、调度以及运维、权限管理等功能。开发流程如下:
- 使用IDE创建计算节点(SQL、MR或Shell任务),编写节点代码,设置节点属性,配置关联节点依赖,配置后可试运行。
- 任务提交节点进入开发环境,进入工作流内。工作流可被人为触发或系统自动调度与运行。节点满足条件后,下发到调度系统的执行引擎Alisa,完成资源分配和执行。
- 开发环境运行无误后,可提交到生产。
SQLSCAN
嵌入D2平台中,在开发提交代码时触发SQLSCAN检音。主要检育如下几项:
- 代码规范美:如命名,生命周期、表注释*代码质量类:调度参数检查、分母为0提醒、NULL值参与计算影响结果提醒、插入字段顺字错误等。
- 代码性能类:扫描大表、重复计算检测等。
规则有强弱之分,触发强规则时代码提交被阻断,必须修复后才能再次提交。触发若规则只会提示出来,但可以继续提交任务。
DQC
数据质量中心,关注数据质量,通过配置数据质量校验规则,在数据处理时对数据质量进行监控和清洗。

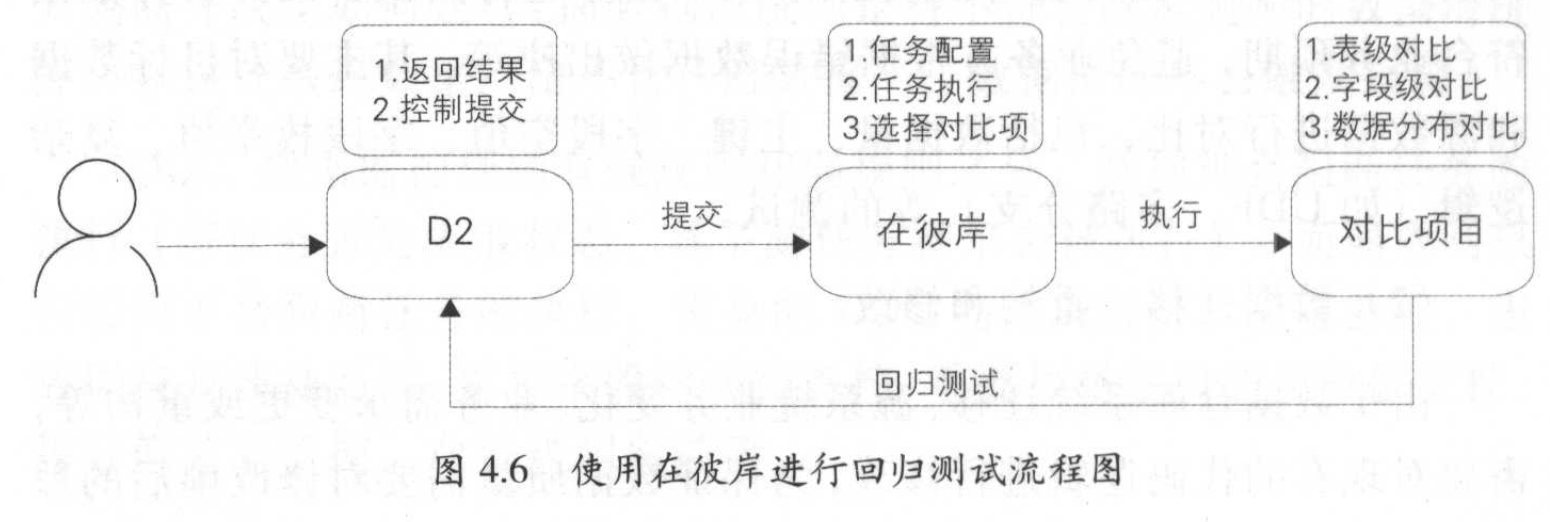
在彼岸
大数据系统自动化测试平台,将通用的、重复性的操作沉淀在测试平台中,提高效率。
数据对比:支持不同集群、异构数据库的表做数据对比。
数据分布:提取表和字段的一些特征值并对比。
数据脱敏:将敏感数据模糊化,实现线上数据脱敏,便于业务联调、数据交换等。
任务调度系統
用户通过D2平台提交发布的任务节点,通过调度系统按任务的运行顺序调度运行
- 调度引擎 (Phoenix Engine):根据任务节点属性和依赖关系进行实例化,生成各类参数的实值和调度树。
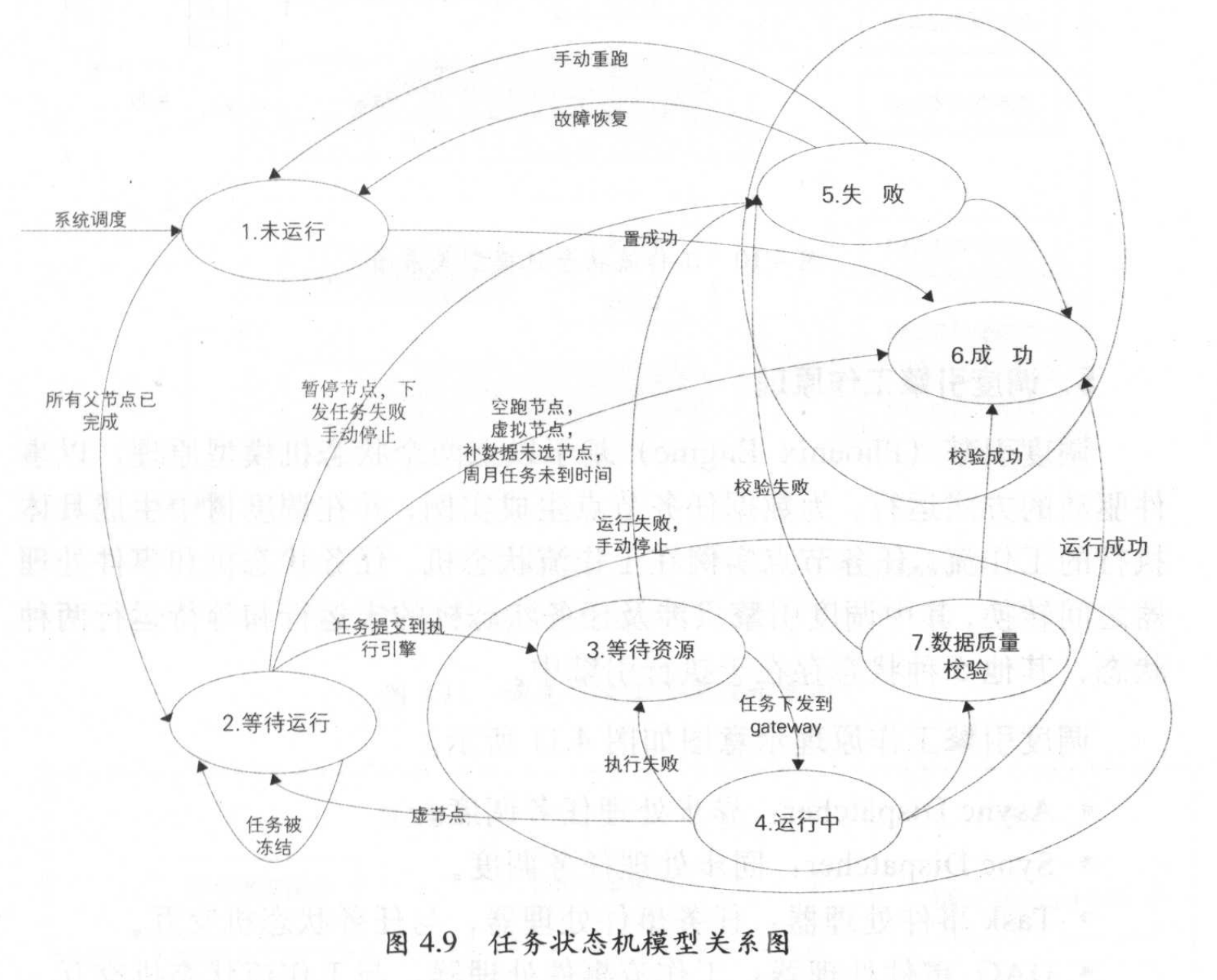
- 任务状态机模型:数据任务节点在整个运行生命周期的状态定义。
- 工作流状态机模型:数据任务节点在调度树中生成的工作流不同状态定义
基于2个模型原理,以事件驱动的方式运行,为数据任务节点生成实例,并在调度树中生成具体执行的工作流。
- 执行引擎(Alisa):根据生成的具体实例和配置信息分配资源,在对应的执行环境中运行节点代码
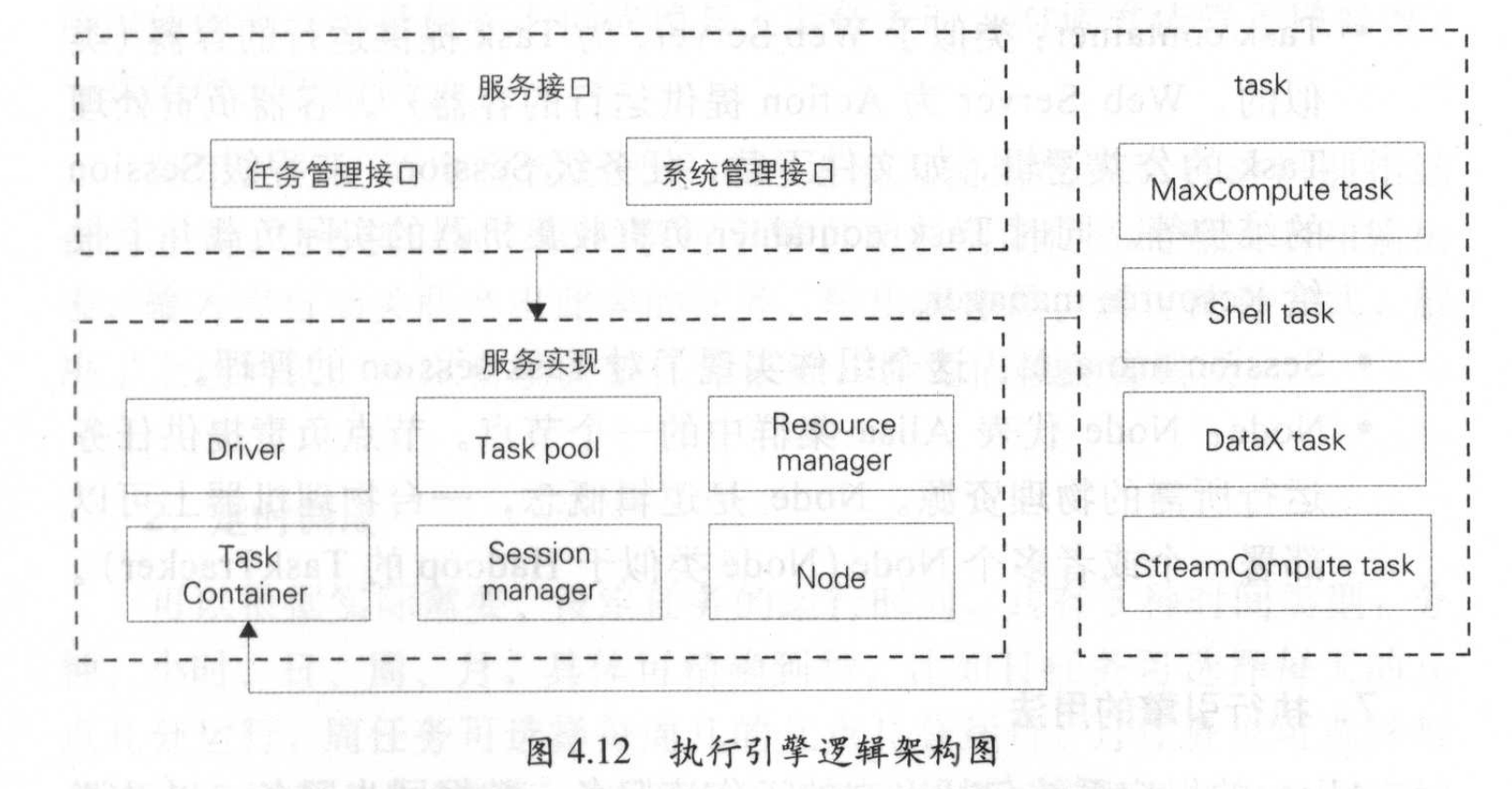
任务管理接口:提供给用户向Alisa中提交、查询和操作离线任务的入口,并获取异步通知。
系统管理接口:系统管理员进行后台管理,包括为集群新增机器、划分咨源组、查询集群咨源、负载、追踪任务状态等。
Driver: Alisa的调度器,实现了上面2个接口,负责任务的调度策略、集群容灾、伸缩、任务失效备缓、负载均衡。
Task Pool: Driver将已提交的任务都放到Task Pool中管理,包括不同状态下的任务,直到任务运行完成才会将其移出。Driver和Node通过TaskPool提供的事件机制进行可靠的通信。
ResourceManager:用于集群整体资源的管理。
Task container:类似Web Server,为任务运行提供容器,负麦处理任务的公共逻辑,例如文件下载,任务级Session、流程级Session的维护等。
Node:代表Alisa集群中的一个节点,节点负责提供任务运行所需的物理资源,Node是逻辑概念,一台物理机上可以布置一个或多个Node。
系统将任务提交到Alisa中后,无需关心任务应该在哪里执行以及如何被执行,降低了系统本身的复杂度。同时其任务可以共享同一个物理集群资源,提高了资源利用效率。如果任务是MaxCompute中的任务,计算实际会提交到MaxCompute集群中,Alisa只作为一个Client。对应的,流计算任务以及Shell、离线数据同步任务、实时同步任务等也会在对应的环境执行。
实时计算
与离线批处理相对的是流式实时处理,是针对时效性较高的场景提供服务的。按照数据延迟情况,数据时效性一股分为三种:
离线:在今天T处理N天之前的数据(N>=1),延迟时间粒度为天,例如Linkdo上的日任务
准实时:在当前小时H处理 N小时之前的数据(N>0,如0.5、1)延迟时间粒度为小时,例如Linkdo上的SEQ任务
实时:在当前时刻处理当前的数据,延迟时间粒度为秒
商线和准实时都可以在批处理系統中实现(如Hadoop、Waxcompute. Spark)等,只是调度周期不一样。实时数据要在流式处理系统中完成
流式处理:指业务系统每产生—条教据;就会立刻被采集并发送到流式任务中进行处理,不需要定时谓度任务来处理数据。流式处理有如下特点:
-
时效性高:延迟粒度在秒级甚至窒秒级,业务方可以在第一时间拿到处理加工后的数据。
-
常驻任务:流式任务属于常驻进程任务工一旦启动后就会一直运行,直到人为停止,所以计算成本比较高。
- 流式任务的数据源是无界的,离线任务的数据源是有界的。因此在数据处理上有一定局限性。
-
性能要求高:如果处理吞吐量跟不上采集量,计算出来的数据失去了实时性,产出的数据的延迟也会越来越高,有可能影响业务方决策。
- 在互联网行业中,需要在数据量快速膨胀的情况下同样保持高吞吐量和低延迟。
-
应用局限性:对于业务逻辑复杂的场桌,例收如双流关联、有数据回滚需求的情况,流式处理无法支持,因此流式处理不能代替离线处理。
流式架构
流式架构需要在不同的子系统之间相互依赖形成一条数据处理链路,才能产出结果最终对外提供实时数据服务。不同的子系统按功能分类可分为如下几
1、数据采集
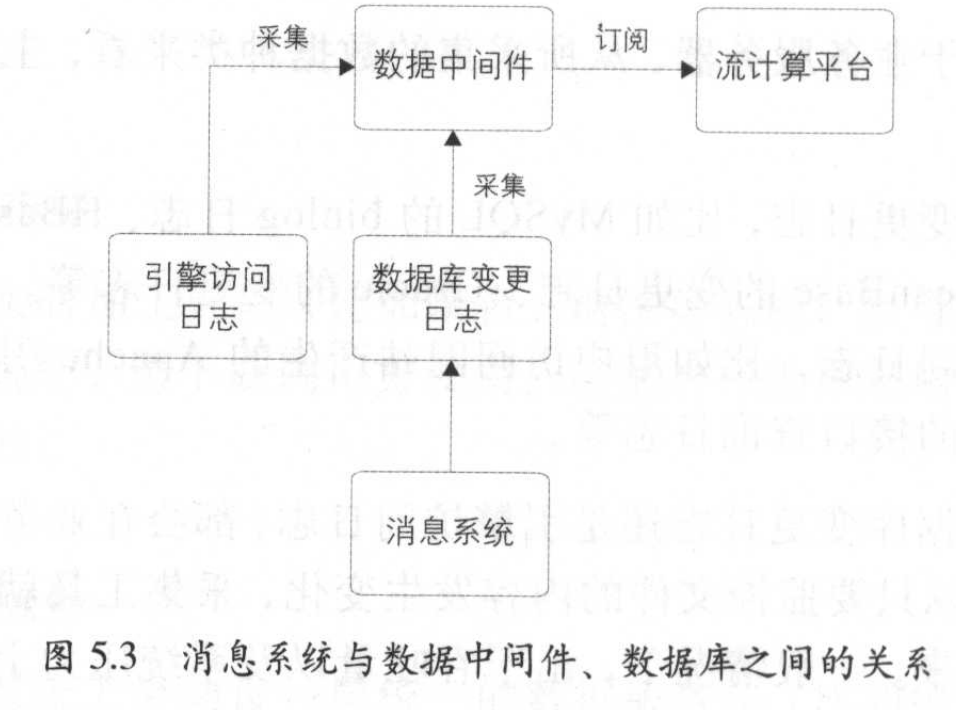
实时计算也需要求目志实时采集,日志均来源于业务服务器,其中主要分为:数据库变更日志&引擎访问日志,采集后落在文件中。只要监控文件内容发生变化,采集工具就可以把最新的数据采集下来。采集时,一般按如下规则:
-
数据大小限制:例如到达512K时,把数据作为新的一批。
-
时间阈值限制:例如30秒写一批,避免在数据量少的情况一直不采集。
这2个条件满足其一即可采集,具体参数根据业务需求设定。数据采集后,需要一个数据中间件分发给下游,例如Kalka、MetaQ、阿里的Time Tunnel。这里涉及2个概念:时效性和吞吐量,等用到了再具体举例。
2、数据处理
一般对流式数据进行处理的系统有:推特开源的Storm、Spark Streaming、Flink, 阿里用的是自研的Stream Compute。实时应用的整个拓扑结构是一个有向无环图,如下图所示:

spout:拓扑的输入,从数据中间件读取数据,根据分发规则发送给下游,可以有多个输入源。
bolt:业务处理单元,可根据处理逻辑分为多个步骤,相互分发时也有自定义规则。
实时任务一股是多线程的,根据业务主键进行分桶处理,大部分计算过程需要的数据都会放在内存中,可大大提高应用的香吐量。以下是实时任务中的典型问题:
去重指标
去重是指删除重复的数据记录,保留唯一的数据记录的过程。为了追求处理性能,计算逻辑—股在内存中完成,中间结果数据也会缓存在内存,这样就会带来内存消耗过多的问题。去重可以遊免重复计算:减少存储空间占用和提高数据处理效率。计算去重时,需要将去重的明细数据保存下来,如果内存中放不下,就需要另想办法:
如果数据是必须要保留下来的,那就通过数据倾斜来处理,将一个节点的内存分到多个节点上,如果数据量非常大但精度要求不高,可以使用去重算法,提高内存使用率。(布隆过滤器、基数估计)
数据倾斜
例如计算一天中全网访容量或者成交额,最终计算的结果只有一个,而这一股是在一个节点上完成的计算任务。而在数据量非常大时,单节点的处理能力是有限的,所以需要对数据进行分桶处理
- 去重指标分桶:通过对去重值进行分桶Hash,相同的值会放到同一个桶里,再把每个桶的值相加得到总值。利用了每个桶的CPU和内存
- 非去重指标分桶:数据随机分发到每个桶,最后把每个桶的值汇总。利用了每个桶的CPU。
事务处理
实时计算是分布式处理的,基本上所有流计算系统都提供了数据自动ACK、失败重发以及事务等机制,以保证数据的幂等性。
-
超时间:数据的处理是投批次来的,每当数据超时时,就会从spout端重发数据。每个批次处理的数据不宜过大,应限流。
-
事务信息: 每批数据都携带事务ID,在重发的情况下,需要开发者自行处理首次到达和重发时的逻辑处理。
-
备份机制:开发人员需要保证内存中的数据可以通过外部存储恢复,因此在计算中用到的中间数据结果都需要备份到外部存储中。
3、数据存储
实时任务在运行过程中,会计算很多维度和指标,这些数据需要放在一个存储系统中作为恢复或关联使用。涉及三种类型的数据:
-
中间计算结果:在数据处理了过程中,有一些状态的保存,用于在发生故障时,从数据库中取出恢复内存现场。
-
最终数据结果:通过ETL处理后的实时结果数据,这些数据是实时更新的,写的频率非常高,可以直接被下游使用。
-
维表数据:离线计算系统中,通过同步工具导入到在线存储系统中,供实时任务来关联流数据。
不同的数据类型,需要选择的数据库也不一样。实时任务一股使用HBase、MangoDB等列式存储系统。这些系统在写数据时先写内存再落磁盘,不管是写或者读甚至并发读都可以达到毫秒级延时。但缺点也比较明显,例如HBase对表的涉及和命名需要一定的讲究。
4、数据服务
实时数据落地到存储系统后,使用方通过统一的数据服务获取到实时数据,调用方不直接连数据库,只使用服务层暴露的接口,无需关心底层取数逻辑的实现。
流式数据模型
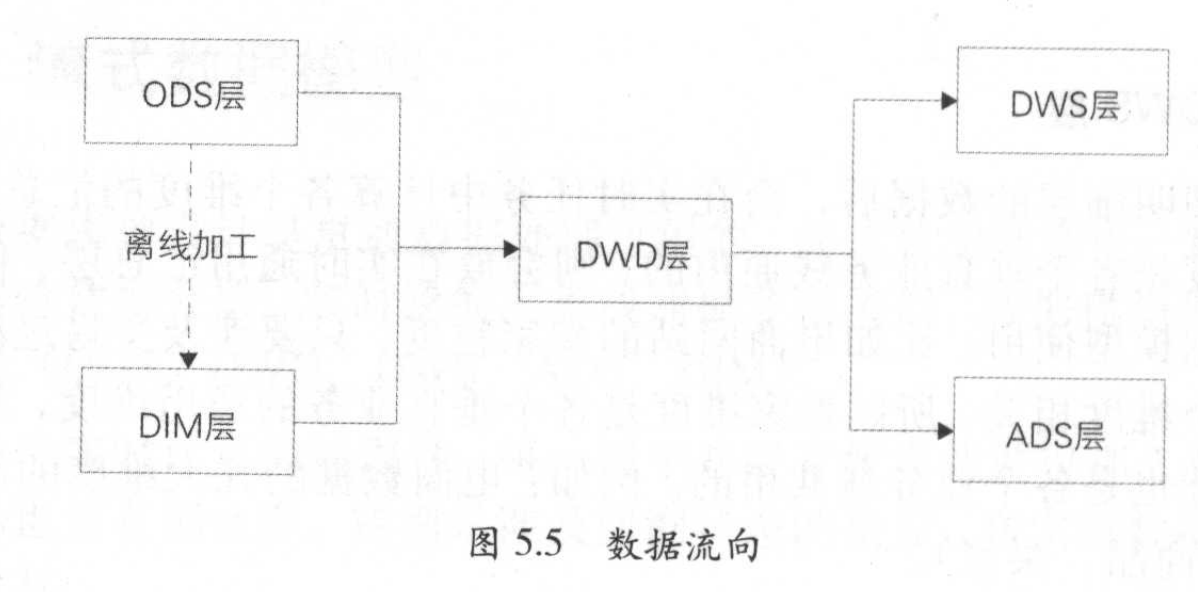
流式数据模型跟离线模型类似,数据模型整体分为5层:
操作数据层ODS:直接从业务系统采集过来的最原始的数据,包含所有业务变更过程,ODS层的事实日志采集和离线日志采集是一致的,同一份数据加工出的指标,口径基本是统一的,可以更方便地对比实时和离线数据。例如原始订单变更记录数据、服务器引擎访问日志
-
事实明细层DWD:在ODS基础上,根据业务过程建模出来,对于访问日志这种没有上下文关系、无需等待过程的记录,会回流到离线系统供下游使用,保证实时与高线数据在ODS和DWD层是一致的。例如:订单支付明细表、退款明细表等
-
汇总数据层DWS:订阅明细层数据后在实时任务中计算各维度的汇总指标,如果维度是各垂直业务线通用的,就会放在实时通用汇总层,作为通用的数据模型使用。例如电商几大维度汇总表:卖家、商品、买家
-
个性化维度汇总层ADS:对于不是特别通用的统计维度数据放在这一层,计算只有自身业务才会关注的维度和指标,常用于—些垂直新业务中,例如淘宝下某个爱逛街、微淘等垂直业务。
-
实时维表层DIM:基本都是从高线维表层导出来的,抽取到在线系統中供实时应用调用。
以电商订单举例说明每一层存储的数据
ODS层:订单粒度的变更过程,一笔订单有多条记录
DWD层:订单粒度的支付记录,一笔订单只有一条记录
DWS层:卖家实时成交金额,一个卖家只有一条记录,并且指标在实时刷新
ADS层:外卖区块的实时成交金额,只有外卖业务使用
DIM层:订单商品类目和行业的对应关系维表
ODS层离线处理完成后,同步至实时计算所使用的的存储系統
ODS和OWD层放至数据中同件共下涉订阅使用
DWS和ADS层落地到在线存储系统中,供下游通过接口调用
大促保障
大促特征:大促是一场对数据计算的高吞吐量、低延时、高保证性、高准确性的挑战。
毫秒级延时:业务方和用户对实时数据非常关注,尤其是在跨零点或者全球直播大屏,这种要求吞吐量和延时兼得的情况,必须要做针对性优化才能满足需求。
洪峰明显:零点开售的峰值陡峰是非常明显的,一般是日常峰值的几十倍。因此对数据处理链路的每个系统都是巨大的桃战,需要在大促前多次对全链路压测和预案梳理,确保系统能够承载住洪峰冲击。
高保障性:只要出现数据延迟或者数据异常问题,业务方反弹较大,会第一时间感知到数据异常。因此在大促期间一股都要求高保障或强保障。对于保障的数据,需要做多链路冗余,从采集、处理到数据服务整个数据链路都需要做物理隔离,任意—条链路出现问题时,都能够无感切换至备链。
公关特性:大促期问数据及时对公众披露是非常重要的,要求实时计算的数据质量非常高,涉及主键过滤、去重的精准和口径统一等一系列问题.
实时任务优化
1、独占资源和共享资源的策略
如果某个任务在运行时80%以上的时间都需要抢咨源,就需要考虑给它分配更多的独占资源,避免抢不到CPU资源导致吞吐量急剧下降
2、合理选择缓存机制,尽量降低读写库次数
内存里读写性能是最好的,让最热和最可能使用的数据留在内存,读写库次数降低后,吞吐量自然上升了。
3、计算单元合并,降低拓扑层级
拓扑结构层级越深性能越差。数据在每个节点传输时,大部分是需要经过序列化和反序列化的,这个过程非常消耗CPU和时间
4、内存对象共享,避免字符串拷贝
海量数据处理时,大部分对象都是以字符串形式存在的,在不同线程间台理共享对象,可大幅降低字符拷贝带来的性能消耗,但要注意不合理使用带来的内存溢出问题.
5、高吞吐量和低延时之问取平衡
高吞吐量和低延时这两个特性是一对矛盾体,当多个读号库操作或者ACK操作合井成一个时,可以大幅降低因为网络请求带来的消耗,不过也会导致延时高一些,需在业务上衡量进行取舍。
数据链路保障
实时数据的处理链路非常长,一个环节出现问题,都会导致实时数据停止更新。实时计算属于分布式计算的一种,单个节点故障是常态。因此为了保证实时数据的可用性,需要对整条计算链路都进行多链路搭建,做到多机房容灾甚至异地容灾。
由于造成链路问题的情况较多,一般不能在秒级定位到原因,因此会通过工具对比多条链路的结果数据,当某条链路出现问题时可以立即发现,然后一键切换到备链,通过推送配置的形式让其秒级生效,整个流程对直播大屏完全透明,用户也感知不到故障发生。
